
SQL 入门笔记(十二)联结表
联结
SQL 最强大的功能之一就是能在数据查询的执行中 联结 (join) 表。联结是利用SQL的 SELECT 能执行的最重要的操作,很好地理联结以及其法是学习 SOL 的极为重要的部分
在能够有效地使用联结前,必须了解关系表以及关系数据库设计的基础知识。下面的介绍并不能涵盖这一主题的所有内容,但作为入门经够了
关系表
理解关系表,最好是来看个例子。有一个包含产品目录的数据库表,其中每类物品占一行。对于每一种物品,要存储的信息包括产品描述、价格,以及供应商
现在有同一供应商生产的多种物品,那么在何处存储供应商名、地址、联系方式呢?将这些数据与产品信息分开存储的理由是:
- 同一供应商生产的每个商品,其供应商数据都是相同的,对每个产品重复此信息既浪费时间又浪费存储空间
- 如果供应商信息发生变化,例如供应商迁址或电话号码变动,只需修改一次即可
- 如果有重复数据(即每种产品都存储供应商信息),则很难保证每次输入该数据的方式都相同,不一致的数据在报表中就很难利用
关健是,相同的数据出现多次决不是一件好事,这是关系数据库设计的基础。关系表的设计就是要把信息分解成多个表,一类数据一个表。各表通过某些共同的值互相关联(所以才叫关系数据库)
在这个例子中可建立两个表:一个存储供应商信息,另一个存储产品信息。Vendors 表包含所有供应商信息,每个供应商占一行,具有唯一的标识。此标识称为 主键(primary key) ,可以是供应商 ID 或任何其他唯一值
Products 表只存储产品信息,除了存储供应商 ID(Vendors 表的主键)外,它不存储其他有关供应商的信息。Vendors 表的主键将 Vendors 表与 Products 表关联,利用供应商 ID 能从 Vendors 表中找出相应供应商的详细信息。
这样做的好处是:
- 供应商信息不重复,不会浪费时间和空间
- 如果供应商信息变动,可以只更新 Vendors 表中的单个记录,相关表中的数据不用改动
- 由于数据不重复,数据显然是一致的,使得处理数据和生成报报表更简单
为什么使用联结
如前所述,将数据分解为多个表能更有效地存储,更方便地处理,并且可伸缩性更好,但这些好处是有代价的
如果数据存储在多个表中,怎样用一条 SELECT 语句就检索出数据呢?
答案是使用联结。简单说,联结是一种机制,用来在一条语句中关系表,因此称为联结 。使用特珠的语法,可以联结多个表返一组输出,联结在运行时关联表中正确的行
说明:使用交互式 DBMS 工具
重要的是,要理解联结不是物理实体。换句话说,它在实际的数据库表中并不存在。DBMS 会根据需要建立联结,它在查询执行期间一直存在。许多 DBMS 提供图形界面,用来交互式地定义表关系。这些工具族来有助于维护引用完整性。在使用关系表时,仅在关系列中插入合法数据是非常重要的。回到这里的例子,如果 Products 表中存储了无效的供应商 ID,则相应的产品不可访问,因为它们没有关联到某个供应商。为避免这种情况发生,可指示数据库只允许在 Products 表的供应商 ID列中出现合法值(即出现在 Vendors 表中的供应商)。引用完整性表示 DBMS 强制实施数据完整性规则,这些规则一般由提供了完整界面的 DBMS 管理
创建联结
创建联结非常简单,指定要联结的所有表以及它们的方式即可
1 | SELECT vend_name, prod_name, prod_price |
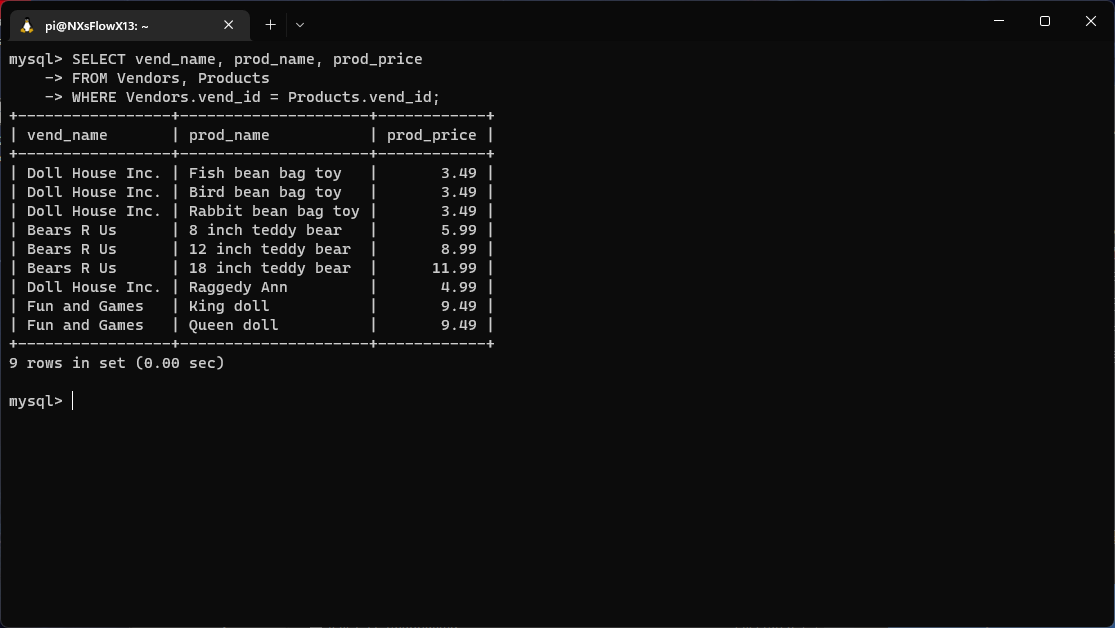
可以看到,SELECT 语句与之前的都不同,它指定的 3 列并不在同一个表中,因此在 FROM 子句中有两个表,并且这两个表用 WHERE 子句联结在一起
WHERE 子句指示 DBMS 将 Vendors 表中的 vend_id 与 Products 表中的 vend_id 匹配起来
警告:完全限定列名
在引用的列可能出现歧义时(例如这个例子),必须使用完全限定列名,不然大多数 DBMS 会返回错误
WHERE 子句的重要性
使用 WHERE 子句建立联结可能有些奇怪,但是实际上有个很充分的理由:WHERE 子句是用来过滤的
可以试一下没有这一子句的情况
1 | SELECT vend_name, prod_name, prod_price |
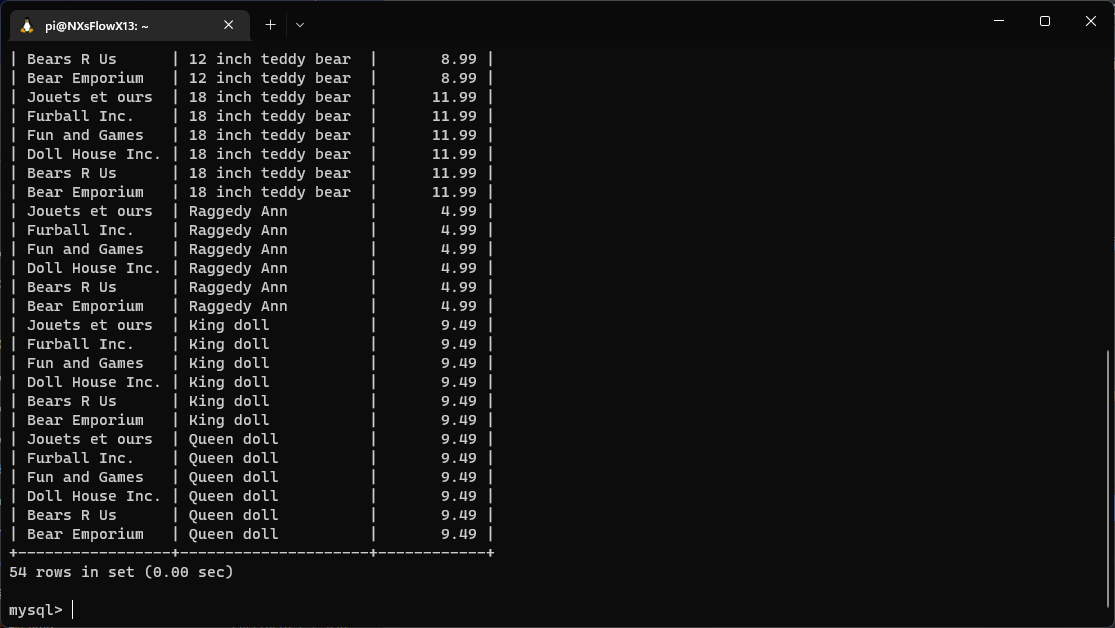
答案是,直接返回了两表的笛卡尔积,将第一个表的每一行都与第二个表的每一行匹配,这也被称为叉联积(cross join) ,但在这里明显不是我们想要的
而 WHERE Vendors.vend_id = Products.vend_id 就是用来过滤出那些恰当的行
内联积
到目前为止使用的联结称为等值联结(equijoin) ,它基于两个表之间的相等测试,这种联结也被称为内联结(inner join)
其实,可以对这种联结使用稍微不同的语法,明确指定联结的类型,下面的 SELECT 语句返回与前面例子完全相同的数据
1 | SELECT vend_name, prod_name, prod_price |
此语句中的 SELECT 与的面的 SELECT 语句相同,但 FROM 子句不同。这里,两个表之间的关系是以 INNER JOIN 指定的部分 FROM 子句。在做用这种语法时,联结系件用特定的 ON 子句而不是 WHERE 子句给出。至于选用哪种语法,请参阅具体的 DBMS 文档。
说明:“正确的”语法
ANST SQL 规范首选 INNER JOIN 语法,之前使用的是简单的等值语法。其实,SQL语言纯正论者是用鄙视的眼光看待简单语法的。这就是说,DBMS 的确支持简单格式和标准格式,我建议你理解这两种
格式,具体使用就看你用哪个更顺手了。
联结多个表
SQL 不限制一条 SELECT 语句中可以联结的表的数目,创建联结的基本规则也相同:首先列出所有表,然后定义表之间的关系
来回顾上一节的例子
1 | SELECT cust_name, cust_contact |
正如上一节所述,子查询并不是执行复杂 SELECT 操作的最有效方法,下面是使用联结的相同查询
1 | SELECT cust_name, cust_contact |
注意:性能考虑
不要联结不必要的表,联结的表越多,性能下降越厉害
注意:联结中表的最大数目
虽然 SQL 本身不限制每个联结的约束中表的最大数目,但实际上许多 DBMS 都有限制,请参阅具体的 DBMS 文档以了解其限制
提示:多做实验
可以看到,执行任一给定的 SQL 操作一般不止一种方法。很少有绝对正确或绝对错误的方法。性能可能会受到操作类型、所使用的 DBMS 、表中数据量、是否存在索引或键等条件的影响。因此,有必要试验不同的选择机制,找出最合适具体情况的方法
说明:联结的列名
在上述所有的例子中,联结的几个列的名字都是一样的,但这实际上不是必须的