不多废话,直入正题
Kitex 的负载均衡相关源码位于 pkg/loadbalance ,具体结构如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 nx@NXsMacBook-Pro kitex % tree pkg/loadbalance pkg/loadbalance ├── consist.go ├── consist_test.go ├── dummy_picker.go ├── interleaved_weighted_round_robin.go ├── iterator.go ├── lbcache │ ├── cache.go │ ├── cache_test.go │ ├── hookable.go │ ├── hookable_test.go │ └── shared_ticker.go ├── loadbalancer.go ├── weighted_balancer.go ├── weighted_balancer_test.go ├── weighted_random.go ├── weighted_random_with_alias_method.go ├── weighted_round_robin.go └── weighted_round_robin_test.go 2 directories, 17 files
我们先去 loadbalancer.go 看见接口定义,感觉还是很清晰的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 type Picker interface { Next(ctx context.Context, request interface {}) discovery.Instance } type Loadbalancer interface { GetPicker(discovery.Result) Picker Name() string } type Rebalancer interface { Rebalance(discovery.Change) Delete(discovery.Change) }
首先 discovery.Instance 就是要负载均衡的基本对象
1 2 3 4 5 6 7 type Instance interface { Address() net.Addr Weight() int Tag(key string ) (value string , exist bool ) }
而 discovery.Result 是一组对象的集合
1 2 3 4 5 6 7 8 type Result struct { Cacheable bool CacheKey string Instances []Instance }
如果你查看 Loadbalancer 的实现,你会找到下面两个实现:
consistBalancer :基于一致性哈希weightedBalancer :基于加权算法
为什么要区分这两个呢?我认为这两者适用的场景不同:
一致性哈希较为复杂,但是能保证会话粘性,也就是相同键的请求总是路由到相同的服务实例
加权算法比较简单,但不能保证会话粘性
本文将分析加权负载均衡器所提供的几种算法
在 weighted_balancer.go 中,我们能找到如下定义
1 2 3 4 5 6 const ( lbKindRoundRobin = iota lbKindInterleaved lbKindRandom lbKindRandomWithAliasMethod )
这里的轮询包含了一般轮询和加权轮询,随机也包含了一般随机和加权随机,所以一共是 6 种算法
轮询 (Round Robin,RR)
预期效果
最简单的负载均衡方式,让流量依次访问各个实例,例如有 3 个实例 abc
那么轮询的访问顺序就 a-b-c-a-b-c-a-b-c... 如此往复
实现
首先来看一般轮询的结构定义
下面的源码来源于 weighted_round_robin.go 和 iterator.go 两个文件,我把它们拼到了一起
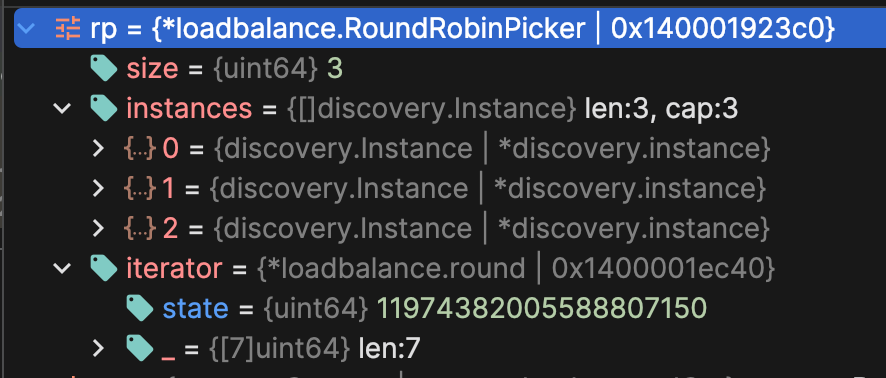
1 2 3 4 5 6 7 8 9 10 11 12 13 type RoundRobinPicker struct { size uint64 instances []discovery.Instance iterator *round } type round struct { state uint64 _ [7 ]uint64 }
你可以看见迭代器 iterator 实际上就是一个数字,但是为了凑成 64 byte 而封装成了结构体,这应该是为了缓存行对齐或者是内存对齐
它的运行过程是这样的
初始化
首先构造 RoundRobinPicker ,并且在迭代器中设置一个随机数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func newRoundRobinPicker (instances []discovery.Instance) size := uint64 (len (instances)) return &RoundRobinPicker{ size: size, instances: instances, iterator: newRandomRound(), } } func newRandomRound () r := &round{ state: fastrand.Uint64(), } return r }
选择实例
然后每次调用 Picker 的 Next 时,都会先调用迭代器的 Next ,把随机数原子加一
1 2 3 func (r *round) uint64 { return atomic.AddUint64(&r.state, 1 ) }
然后,在把这个数对 size 取模,返回对应编号的实例
1 2 3 4 5 6 7 8 func (rp *RoundRobinPicker) interface {}) (ins discovery.Instance) { if rp.size == 0 { return nil } idx := rp.iterator.Next() % rp.size ins = rp.instances[idx] return ins }
如此往复,便能得到预期的效果
预期效果
加权轮询就是每个实例都有权重,例如 abc 的权重分别是 { 5, 1, 1 }
可以构造出序列 { c, b, a, a, a, a, a } 实现按比例分配流量,但是这会让 a 被短暂持续访问
于是就有了平滑加权轮询,将 a 分散分布,而不是堆在一起
如注释所说,Kitex 使用的是平滑加权轮询,准确来说,使用的是 毅松(GitHub@wangfakang)的VNSWRR
实现
先看结构定义
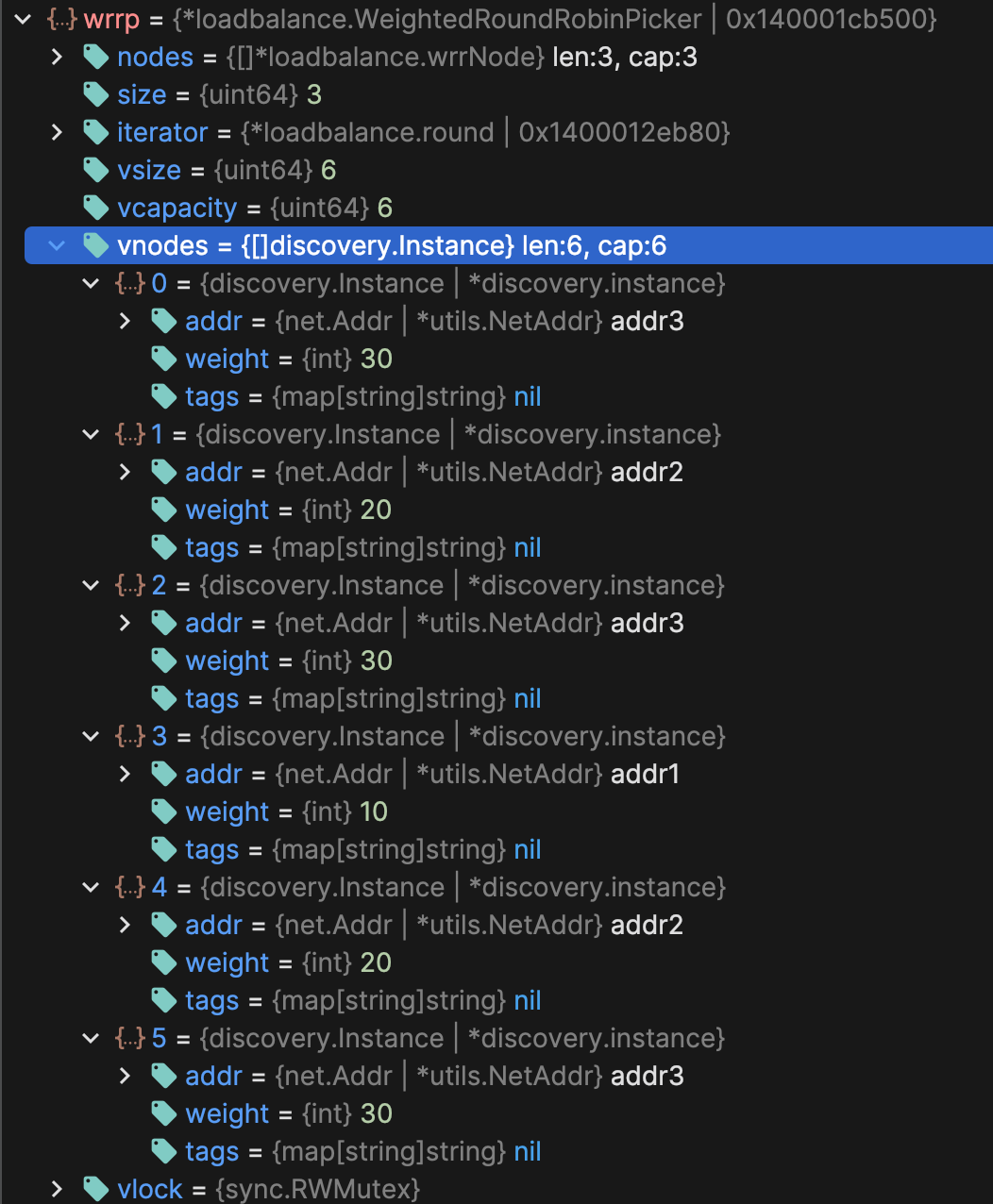
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type WeightedRoundRobinPicker struct { nodes []*wrrNode size uint64 iterator *round vsize uint64 vcapacity uint64 vnodes []discovery.Instance vlock sync.RWMutex } type wrrNode struct { discovery.Instance current int }
wrrNodecurrent字段用于在算法中暂存当前权重的动态值WeightedRoundRobinPickernodes)、有效虚拟节点数(vsize)、虚拟节点容量(vcapacity),以及预计算的虚拟节点数组(vnodes)
初始化
首先将输入的 instances 以乱序存入 nodes ,同时求出最大公约数得到需要的虚拟节点个数
例如权重 { 10, 20, 30} ,最大公约数是 10,然后用总和 60/10 得到至少需要 6 个虚拟节点
最后再调用 buildVirtualWrrNodes 方法在 vnodes 中构建虚拟节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func newWeightedRoundRobinPicker (instances []discovery.Instance) wrrp := new (WeightedRoundRobinPicker) wrrp.iterator = newRound() wrrp.size = uint64 (len (instances)) wrrp.nodes = make ([]*wrrNode, wrrp.size) offset := fastrand.Uint64n(wrrp.size) totalWeight := 0 gcd := 0 for idx := uint64 (0 ); idx < wrrp.size; idx++ { ins := instances[(idx+offset)%wrrp.size] totalWeight += ins.Weight() gcd = gcdInt(gcd, ins.Weight()) wrrp.nodes[idx] = &wrrNode{ Instance: ins, current: 0 , } } wrrp.vcapacity = uint64 (totalWeight / gcd) wrrp.vnodes = make ([]discovery.Instance, wrrp.vcapacity) wrrp.buildVirtualWrrNodes(wrrVNodesBatchSize) return wrrp } const wrrVNodesBatchSize = 500
那么具体来说 buildVirtualWrrNodes 是怎么处理的呢?
他并不会一次构建出全部的虚拟节点(将构建任务分散,轮询时逐步构建),而是先确定一个构建目标(每次向前构建 wrrVNodesBatchSize 个)
然后从当前已有的位置开始,逐个构建到目标位置
1 2 3 4 5 6 7 8 9 10 11 12 13 func (wp *WeightedRoundRobinPicker) uint64 ) { if vtarget > wp.vcapacity { vtarget = wp.vcapacity } for i := wp.vsize; i < vtarget; i++ { wp.vnodes[i] = nextWrrNode(wp.nodes).Instance } wp.vsize = vtarget }
而构建每个虚拟节点时都会调用一次 nextWrrNode ,它的工作流程如下:
增加当前权重 :对于节点列表(nodes)中的每个节点,函数首先将节点的静态权重(node.Weight())加到它的当前权重(node.current)上
这个步骤是在每次选择过程中为所有节点平等地增加权重,确保长期内权重较高的节点能获得更多的选择机会
选择最大当前权重的节点 :在所有节点的当前权重被更新后,函数遍历节点列表,选择当前权重(current)最高的节点作为本次选择的节点
这确保了每次都倾向于选择当前权重相对较高的节点,从而反映了节点的权重比例
减去总权重 :在选择了当前权重最高的节点后,函数会从该节点的当前权重中减去所有节点的静态权重之和
这一步骤是关键,它使得被选中的节点在下一轮选择中的优势减少,防止它连续被过度选择,从而给其他节点以被选择的机会,实现平滑的效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func nextWrrNode (nodes []*wrrNode) maxCurrent := 0 totalWeight := 0 for _, node := range nodes { node.current += node.Weight() totalWeight += node.Weight() if selected == nil || node.current > maxCurrent { selected = node maxCurrent = node.current } } if selected == nil { return nil } selected.current -= totalWeight return selected }
构建完成后的虚拟列表,3 个 30 权重的,2 个 20 权重的,1 个 10 权重的,同时很平滑
选择实例
现在 Next 方法就比较好理解了,和轮询一样依次遍历虚拟节点,无非就是两种情况:
需要节点已经构建,直接返回
需要的节点还没构建,这时需要调用构建函数往前推进一些
但是由于并发的存在,需要有一些锁的处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func (wp *WeightedRoundRobinPicker) interface {}) (ins discovery.Instance) { idx := wp.iterator.Next() % wp.vcapacity wp.vlock.RLock() ins = wp.vnodes[idx] wp.vlock.RUnlock() if ins != nil { return ins } wp.vlock.Lock() defer wp.vlock.Unlock() if wp.vnodes[idx] != nil { return wp.vnodes[idx] } vtarget := wp.vsize + wrrVNodesBatchSize if idx >= vtarget { vtarget = idx + 1 } wp.buildVirtualWrrNodes(vtarget) return wp.vnodes[idx] }
为什么要检查一下需求位置是否超过了计划构建的位置呢?每次都已经计划往后构建 500 个了呀
我猜测是在高并发环境下,可能同时有超过 500 个获取请求,这时需求位置就超过了计划位置,需要构建超过 500 个
这也是前面要再次检查协程是否已经填充了需求位置的虚拟节点的原因
预期效果
也是加权轮询,但是 WRR 的空间复杂度是 O ( ∑ i n s t a n c e . w e i g h t g c d ( i n s t a n c e . w e i g h t ) ) O(\dfrac{\sum {instance.weight}}{gcd(instance.weight)}) O ( g c d ( in s t an ce . w e i g h t ) ∑ in s t an ce . w e i g h t ) O ( l e n ( i n s t a n c e ) ) O(len(instance)) O ( l e n ( in s t an ce ))
虽然时间复杂度加了点常数,但是在实例权重非常大的情况下很节省空间
不过这种情况感觉也不是很多,所以默认算法还是 WRR
实现
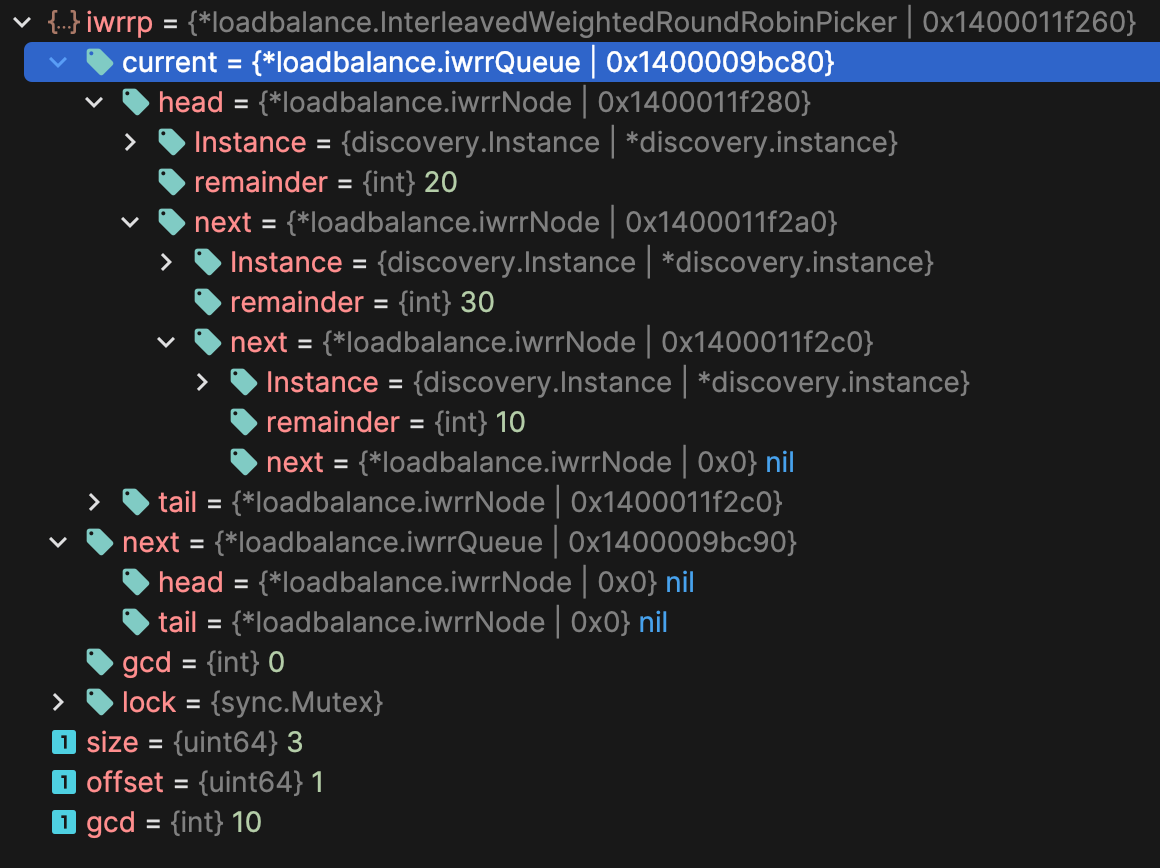
你已经看见了,Kitex 使用的 IWRR 的只有两个队列:当前队列和下一次队列
这并不是标准的 IWRR,它放弃了平滑特性,理由是在大流量下平滑特性并有没什么作用,一个循环会在很短的时间内完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 type iwrrNode struct { discovery.Instance remainder int next *iwrrNode } type iwrrQueue struct { head *iwrrNode tail *iwrrNode } type InterleavedWeightedRoundRobinPicker struct { current *iwrrQueue next *iwrrQueue gcd int lock sync.Mutex } func newIwrrQueue () return &iwrrQueue{}}func (q *iwrrQueue) func (q *iwrrQueue) func (q *iwrrQueue) bool { }
iwrrNode : 表示单个服务实例及其剩余权重。每个节点包括实例信息、剩余权重(remainder),和指向下一个节点的指针(next)iwrrQueue : 管理iwrrNode节点的队列,支持入队(enqueue)和出队(dequeue)操作。队列维护了头节点(head)和尾节点(tail)的引用,以支持高效的操作InterleavedWeightedRoundRobinPicker : 实现了交错加权轮询算法的选择器。它维护两个队列(current和next),以及所有实例权重的最大公约数(gcd)
初始化
将实例乱序放入当前队列中,并将 remainder 初始化为实例权重,同时计算 gcd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func newInterleavedWeightedRoundRobinPicker (instances []discovery.Instance) iwrrp := new (InterleavedWeightedRoundRobinPicker) iwrrp.current = newIwrrQueue() iwrrp.next = newIwrrQueue() size := uint64 (len (instances)) offset := fastrand.Uint64n(size) gcd := 0 for idx := uint64 (0 ); idx < size; idx++ { ins := instances[(idx+offset)%size] gcd = gcdInt(gcd, ins.Weight()) iwrrp.current.enqueue(&iwrrNode{ Instance: ins, remainder: ins.Weight(), }) } iwrrp.gcd = gcd return iwrrp }
选择实例
每次被选中后都会减少 remainder (使用 gcd 来缩短周期)
当 remainder为 0 时表示当前周期内不可调度,将其放到下一次队列中
当当前队列为空时表示当前周期所有元素都被按权重选择过了,此时对换当前队列和下一次队列开始新一轮周期
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (ip *InterleavedWeightedRoundRobinPicker) interface {}) discovery.Instance { ip.lock.Lock() defer ip.lock.Unlock() if ip.current.empty() { ip.current, ip.next = ip.next, ip.current } node := ip.current.dequeue() node.remainder -= ip.gcd if node.remainder > 0 { ip.current.enqueue(node) } else { node.remainder = node.Instance.Weight() ip.next.enqueue(node) } return node.Instance }
由于始终复用节点,所以初始化后无需申请新的空间
随机(Random)
预期效果
非常朴素的随机分配
实现
1 2 3 type randomPicker struct { instances []discovery.Instance }
初始化
1 2 3 4 5 func newRandomPicker (instances []discovery.Instance) return &randomPicker{ instances: instances, } }
选择实例
1 2 3 4 5 func (rp *randomPicker) interface {}) (ins discovery.Instance) { idx := fastrand.Intn(len (rp.instances)) return rp.instances[idx] }
加权随机(Weighted Random)
预期效果
基于随机实现的加权负载均衡,唯一的好处就是没有空间占用,缺点是时间复杂度很高
具体来说就是模拟了 累积分布函数(CDF) 的行为
实现
1 2 3 4 type weightedRandomPicker struct { instances []discovery.Instance weightSum int }
初始化
1 2 3 4 5 6 func newWeightedRandomPickerWithSum (instances []discovery.Instance, weightSum int ) return &weightedRandomPicker{ instances: instances, weightSum: weightSum, } }
选择实例
1 2 3 4 5 6 7 8 9 10 11 func (wp *weightedRandomPicker) interface {}) (ins discovery.Instance) { weight := fastrand.Intn(wp.weightSum) for i := 0 ; i < len (wp.instances); i++ { weight -= wp.instances[i].Weight() if weight < 0 { return wp.instances[i] } } return nil }
如你所见,这个算法是我贡献的哈哈哈😋
预期效果
在选取阶段可以做到常数极低的 O(1) 的时间复杂度
实现
这个算法的实现其实既简单又复杂,简单在只需依托输入构建一个别名表,每次查表就完了
1 2 3 4 5 6 type AliasMethodPicker struct { instances []discovery.Instance weightSum int alias []int prob []float64 }
初始化
别名表的构建过程有点复杂,具体可以看我博客 飞镖、骰子和硬币:从离散分布中抽样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 func newAliasMethodPicker (instances []discovery.Instance, weightSum int ) picker := &AliasMethodPicker{ instances: instances, weightSum: weightSum, } picker.init() return picker } func (a *AliasMethodPicker) n := len (a.instances) a.alias = make ([]int , n) a.prob = make ([]float64 , n) totalWeight := a.weightSum scaledProb := make ([]float64 , n) small := make ([]int , 0 , n) large := make ([]int , 0 , n) for i, instance := range a.instances { scaledProb[i] = float64 (instance.Weight()) * float64 (n) / float64 (totalWeight) if scaledProb[i] < 1.0 { small = append (small, i) } else { large = append (large, i) } } for len (small) > 0 && len (large) > 0 { l := small[len (small)-1 ] small = small[:len (small)-1 ] g := large[len (large)-1 ] large = large[:len (large)-1 ] a.prob[l] = scaledProb[l] a.alias[l] = g scaledProb[g] -= 1.0 - scaledProb[l] if scaledProb[g] < 1.0 { small = append (small, g) } else { large = append (large, g) } } for len (large) > 0 { g := large[len (large)-1 ] large = large[:len (large)-1 ] a.prob[g] = 1.0 } for len (small) > 0 { l := small[len (small)-1 ] small = small[:len (small)-1 ] a.prob[l] = 1.0 } }
选择实例
这个就非常简单了,取随机数然后查表就行
1 2 3 4 5 6 7 8 func (a *AliasMethodPicker) interface {}) discovery.Instance { i := fastrand.Intn(len (a.instances)) if fastrand.Float64() < a.prob[i] { return a.instances[i] } return a.instances[a.alias[i]] }
总结
初始化阶段的 Benchmark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 /Users/nx/Library/Caches/JetBrains/GoLand2023.3/tmp/GoLand/___github_com_cloudwego_kitex_pkg_loadbalance__BenchmarkGetPicker.test -test.v -test.paniconexit0 -test.bench ^\QBenchmarkGetPicker\E$ -test.run ^$ goos: darwin goarch: arm64 pkg: github.com/cloudwego/kitex/pkg/loadbalance BenchmarkGetPicker BenchmarkGetPicker/weight_round_robin BenchmarkGetPicker/weight_round_robin-8 222835 5348 ns/op 16496 B/op 3 allocs/op BenchmarkGetPicker/weight_random BenchmarkGetPicker/weight_random-8 233304 5194 ns/op 16408 B/op 2 allocs/op BenchmarkGetPicker/weight_random_with_alias_method BenchmarkGetPicker/weight_random_with_alias_method-8 232458 5375 ns/op 16408 B/op 2 allocs/op BenchmarkGetPicker/interleaved_weighted_round_robin BenchmarkGetPicker/interleaved_weighted_round_robin-8 223707 5308 ns/op 16496 B/op 3 allocs/op PASS 进程 已完成,退出代码为 0
选择实例阶段的 Benchmark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 /Users/nx/Library/Caches/JetBrains/GoLand2023.3/tmp/GoLand/___github_com_cloudwego_kitex_pkg_loadbalance__BenchmarkWeightedPicker_Next.test -test.v -test.paniconexit0 -test.bench ^\QBenchmarkWeightedPicker_Next\E$ -test.run ^$ goos: darwin goarch: arm64 pkg: github.com/cloudwego/kitex/pkg/loadbalance BenchmarkWeightedPicker_Next BenchmarkWeightedPicker_Next/weight_round_robin BenchmarkWeightedPicker_Next/weight_round_robin/10ins BenchmarkWeightedPicker_Next/weight_round_robin/10ins-8 81600734 14.25 ns/op BenchmarkWeightedPicker_Next/weight_round_robin/100ins BenchmarkWeightedPicker_Next/weight_round_robin/100ins-8 85023469 14.17 ns/op BenchmarkWeightedPicker_Next/weight_round_robin/1000ins BenchmarkWeightedPicker_Next/weight_round_robin/1000ins-8 85418442 14.10 ns/op BenchmarkWeightedPicker_Next/weight_round_robin/10000ins BenchmarkWeightedPicker_Next/weight_round_robin/10000ins-8 35655 33368 ns/op BenchmarkWeightedPicker_Next/weight_random BenchmarkWeightedPicker_Next/weight_random/10ins BenchmarkWeightedPicker_Next/weight_random/10ins-8 47241925 25.41 ns/op BenchmarkWeightedPicker_Next/weight_random/100ins BenchmarkWeightedPicker_Next/weight_random/100ins-8 9708295 123.2 ns/op BenchmarkWeightedPicker_Next/weight_random/1000ins BenchmarkWeightedPicker_Next/weight_random/1000ins-8 1000000 1055 ns/op BenchmarkWeightedPicker_Next/weight_random/10000ins BenchmarkWeightedPicker_Next/weight_random/10000ins-8 110542 10613 ns/op BenchmarkWeightedPicker_Next/weight_random_with_alias_method BenchmarkWeightedPicker_Next/weight_random_with_alias_method/10ins BenchmarkWeightedPicker_Next/weight_random_with_alias_method/10ins-8 90827661 12.36 ns/op BenchmarkWeightedPicker_Next/weight_random_with_alias_method/100ins BenchmarkWeightedPicker_Next/weight_random_with_alias_method/100ins-8 95986561 12.52 ns/op BenchmarkWeightedPicker_Next/weight_random_with_alias_method/1000ins BenchmarkWeightedPicker_Next/weight_random_with_alias_method/1000ins-8 96050268 12.55 ns/op BenchmarkWeightedPicker_Next/weight_random_with_alias_method/10000ins BenchmarkWeightedPicker_Next/weight_random_with_alias_method/10000ins-8 95397718 12.64 ns/op BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/10ins BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/10ins-8 87128834 14.76 ns/op BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/100ins BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/100ins-8 81406752 13.98 ns/op BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/1000ins BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/1000ins-8 85486323 14.07 ns/op BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/10000ins BenchmarkWeightedPicker_Next/interleaved_weighted_round_robin/10000ins-8 86139339 14.06 ns/op PASS 进程 已完成,退出代码为 0
看上去还是我写的 Alias Method 最好哈哈哈
当时导师让我把默认算法改成 Alias Method,我没改,现在有点后悔了 XD
PS:Alias Method 在 Go1.22 版本下会有巨大的性能倒退(我控制变量了一晚上才发现是 Go 版本的问题),究其原因是它所依赖的 fastrand,而 fastrand 直接依赖于 runtime.fastrand ,具体原因请看我的 PR:bytedance/gopkg#206