
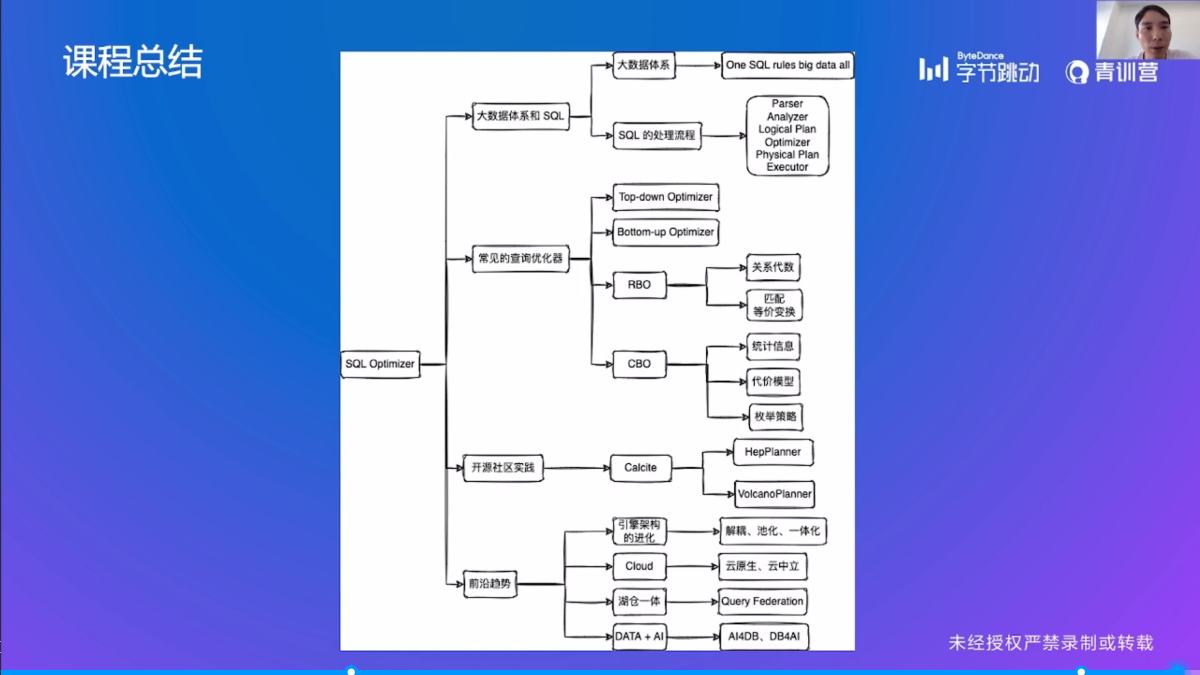
『字节青训营-4th』L1:SQL Optimizer 解析
相关链接
🎶 学员手册:【大数据专场 学习资料一】第四届字节跳动青训营 - 掘金
大数据体系和 SQL
大数据体系
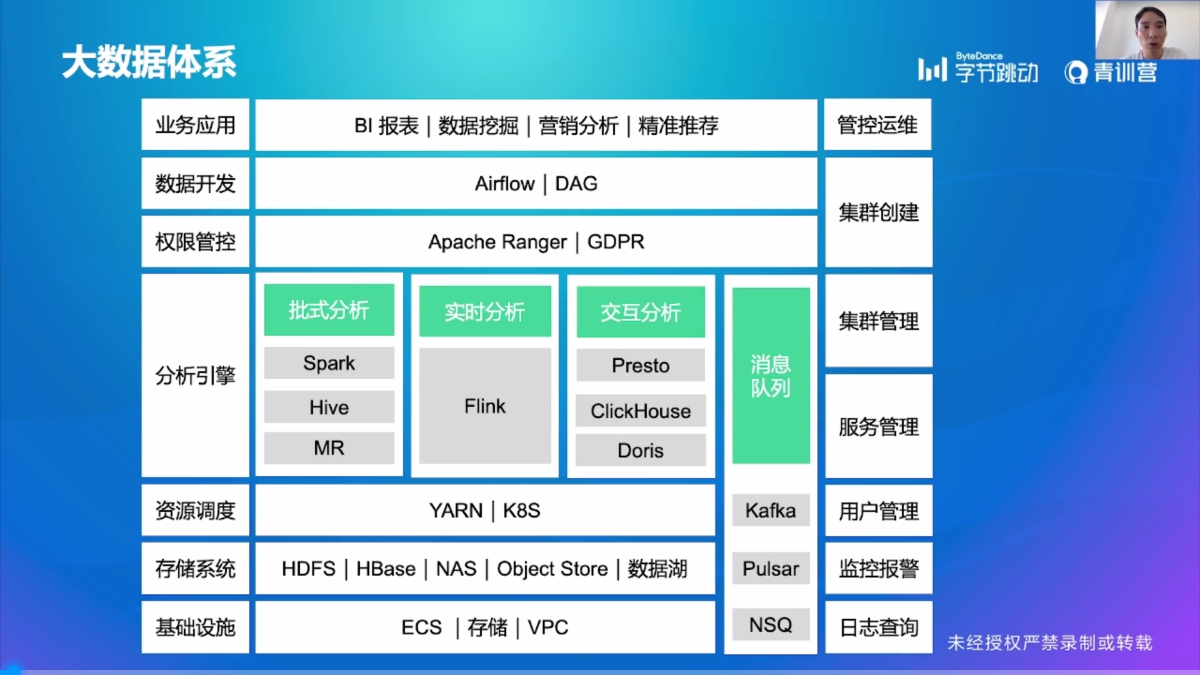
其中消息队列用于解耦存储与计算,本次青训营会从分析引擎开始展开,然后是存储、消息队列与资源调度
那么,为什么要把 SQL 优化器放在第一节课讲呢?
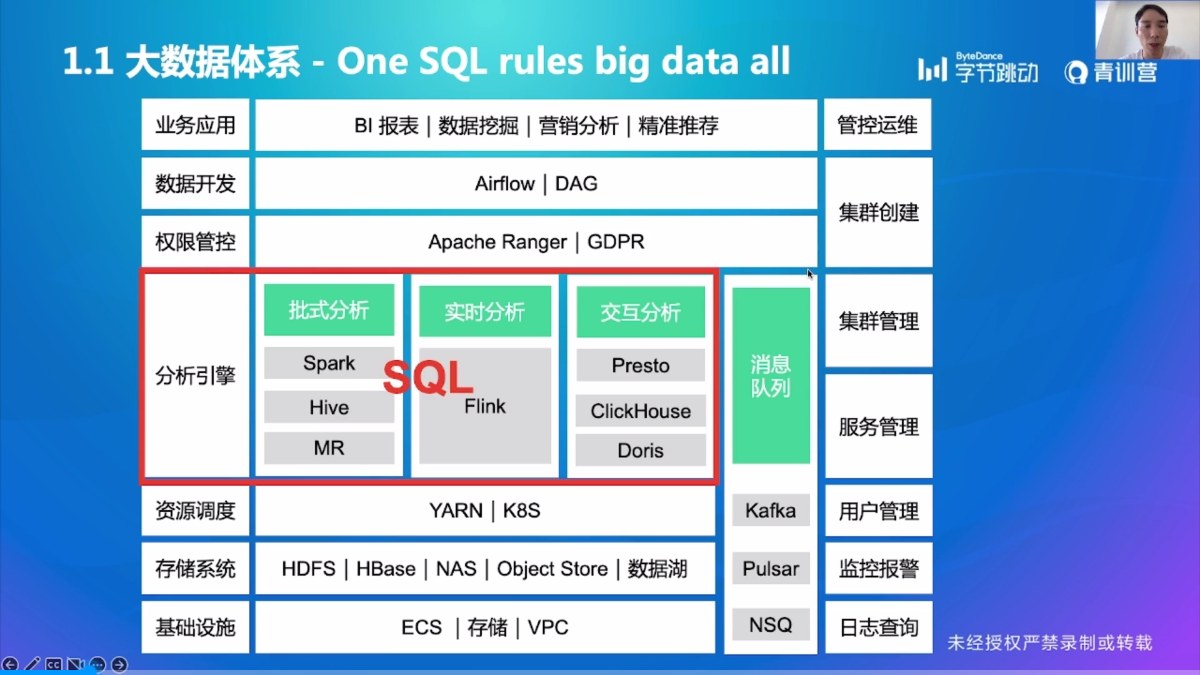
- 首先,SQL 是非常流行的,而且简单,包括数据分析师和挖掘师都在用,他们可能不会使用 Python之类的通用语言,但是他们可以很方便地使用一条 SQL 去处理数据,得到他们想要的结果
- 并且,SQL 是很多系统都支持的接口,而且 SQL 已经成为了大数据方面的通用接口。很多分析引擎一开始并不支持 SQL ,但现在都渐渐地提供了 SQL 接口
也就是说, One SQL rules big data all (通过 SQL 处理所有的大数据)
所以 SQL 在大数据中是非常重要的,下面将介绍 SQL 的处理流程
SQL 的处理流程
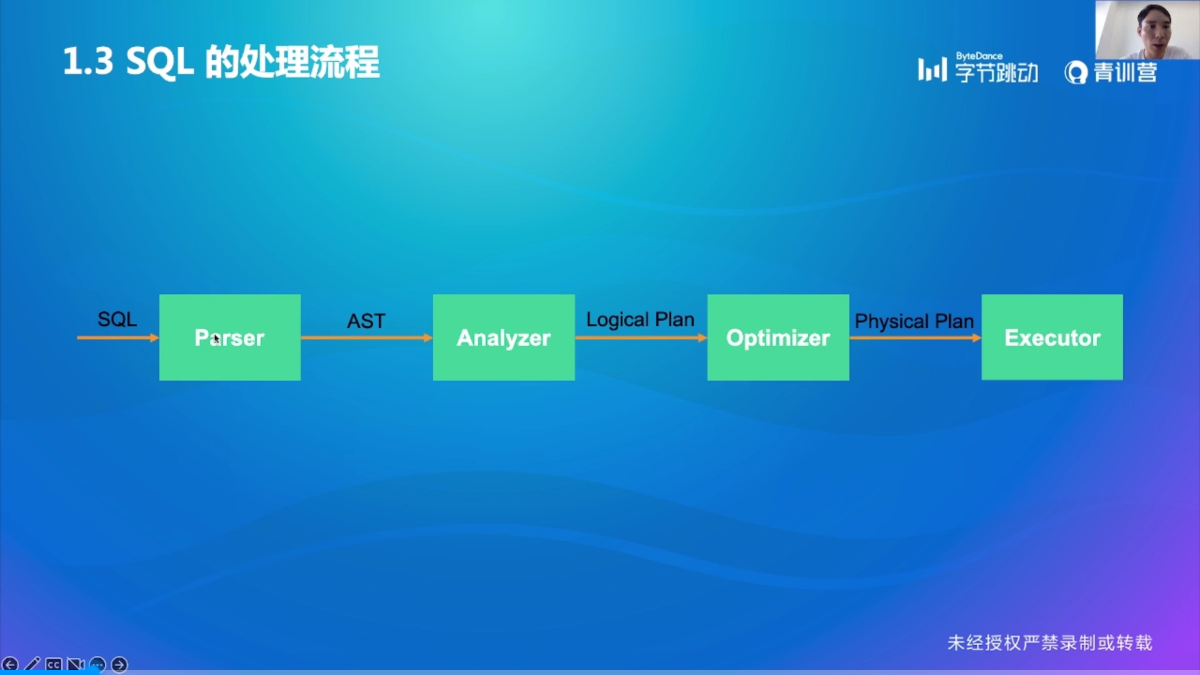
首先,先通过 Parser 变成抽象语法树(Abstract Syntax Tree,AST),之后通过 Analyzer 变成逻辑计划(Logical Plan),再通过 Optimizer 变成物理计划(Physical Plan),最后交给 Executor 来执行
Parser
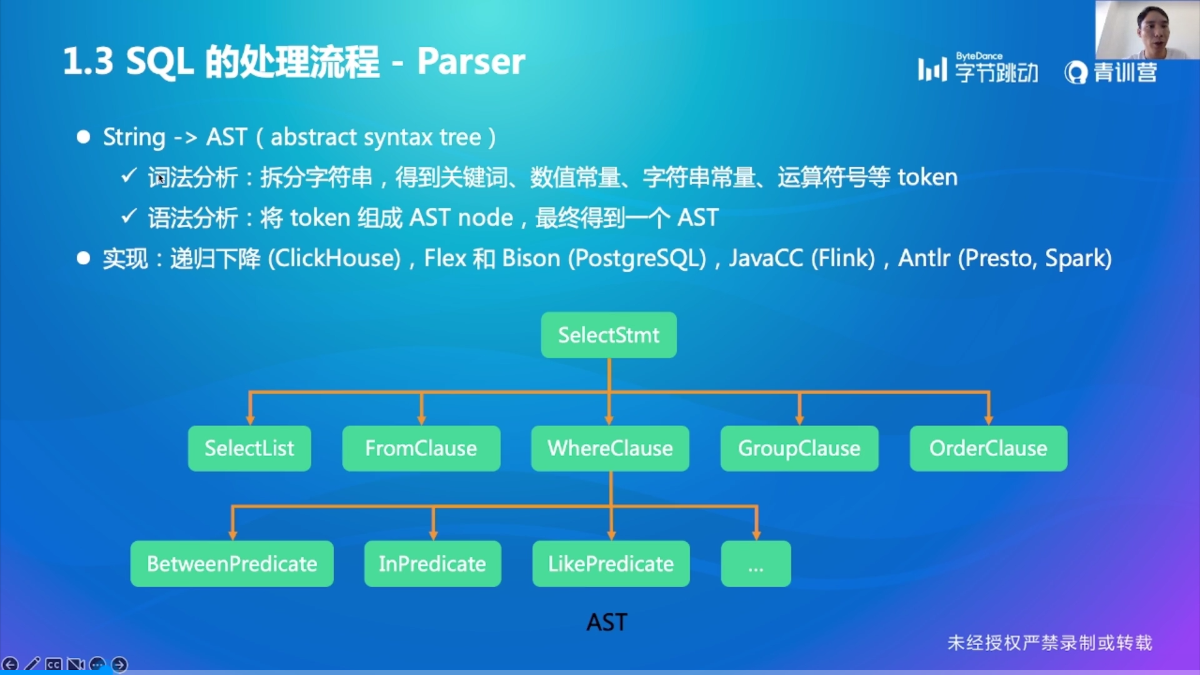
死去的编译原理突然开始攻击我(bushi
Analyzer
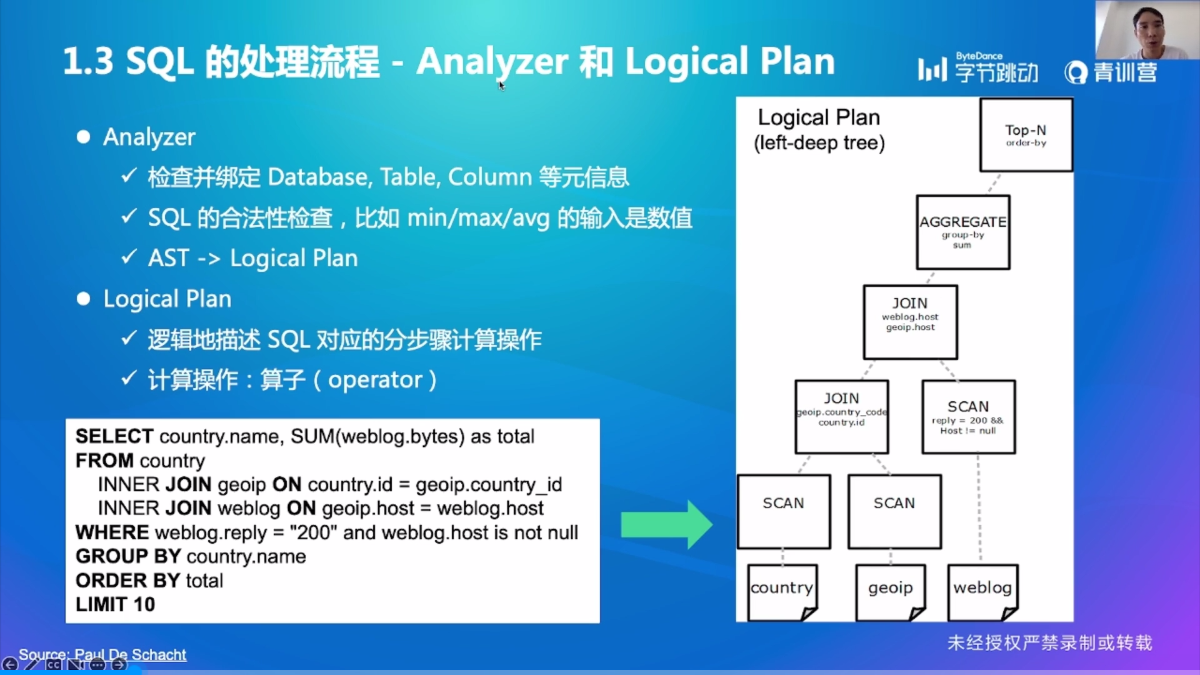
逻辑地:只是说明了要干什么,但是没有确定用什么算法实现(例如排序)
Optimizer

Executor
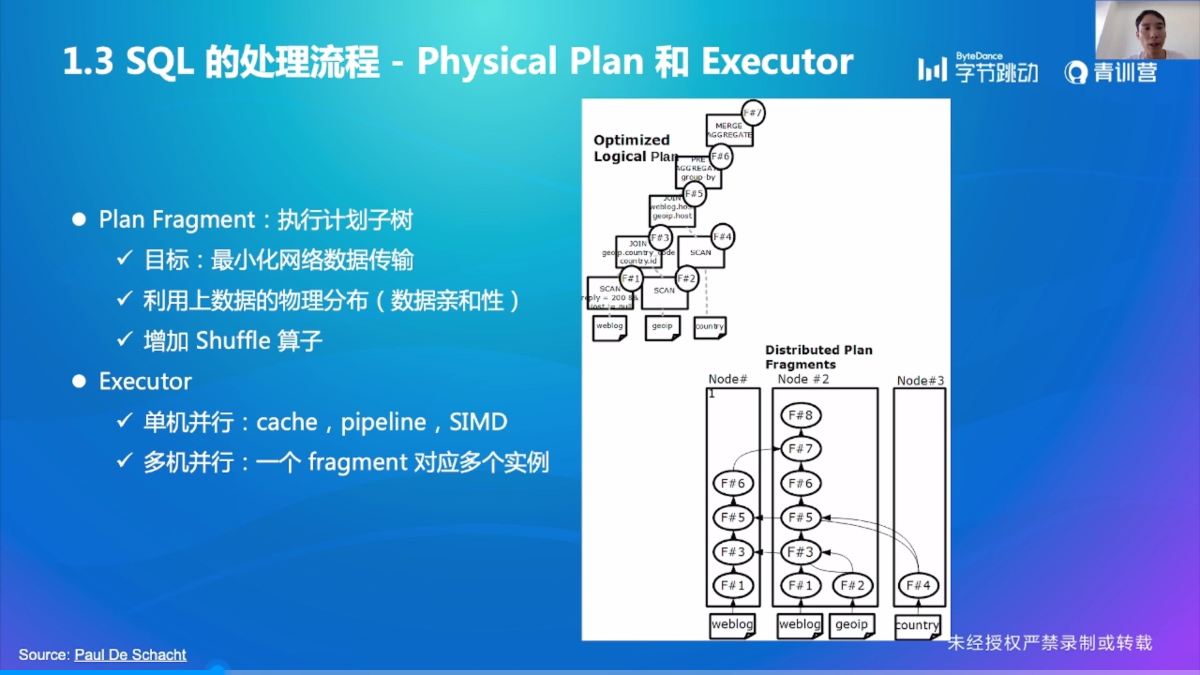
小结

常规的查询优化器
查询优化器分类

两种分类方法
- 按遍历树的方向分
- 按优化方法分
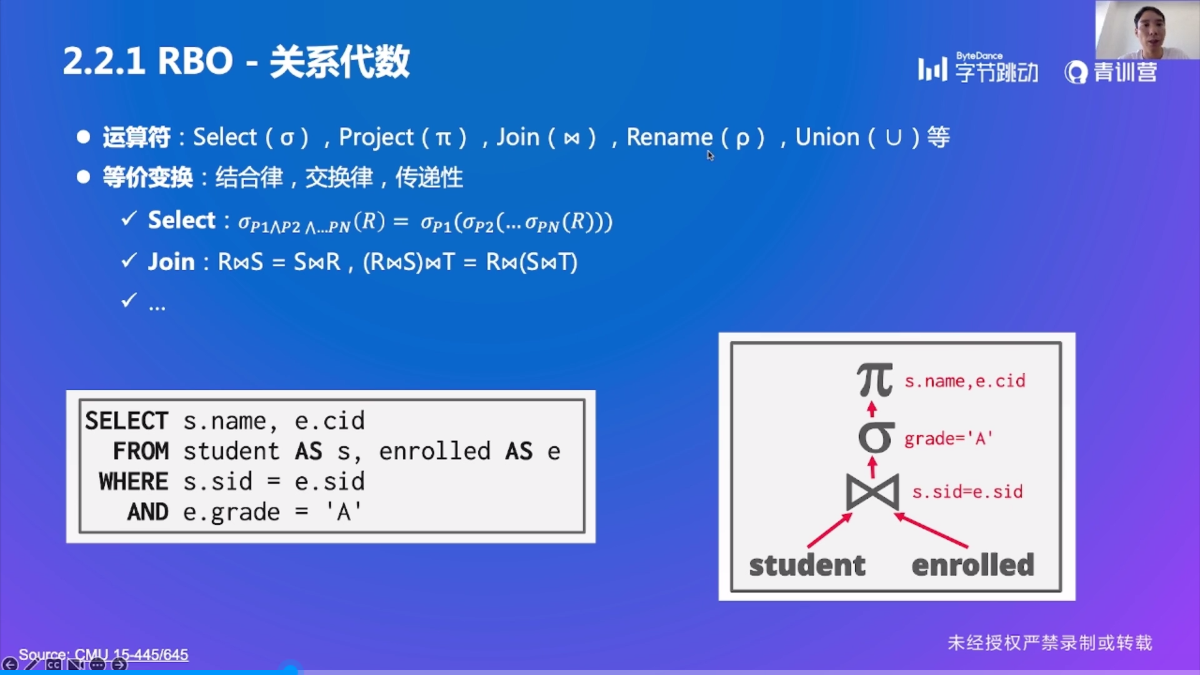
RBO(基于规则的优化)
这些规则只是经验规则,是总结出来的,甚至可能反向优化(
前提知识:关系代数
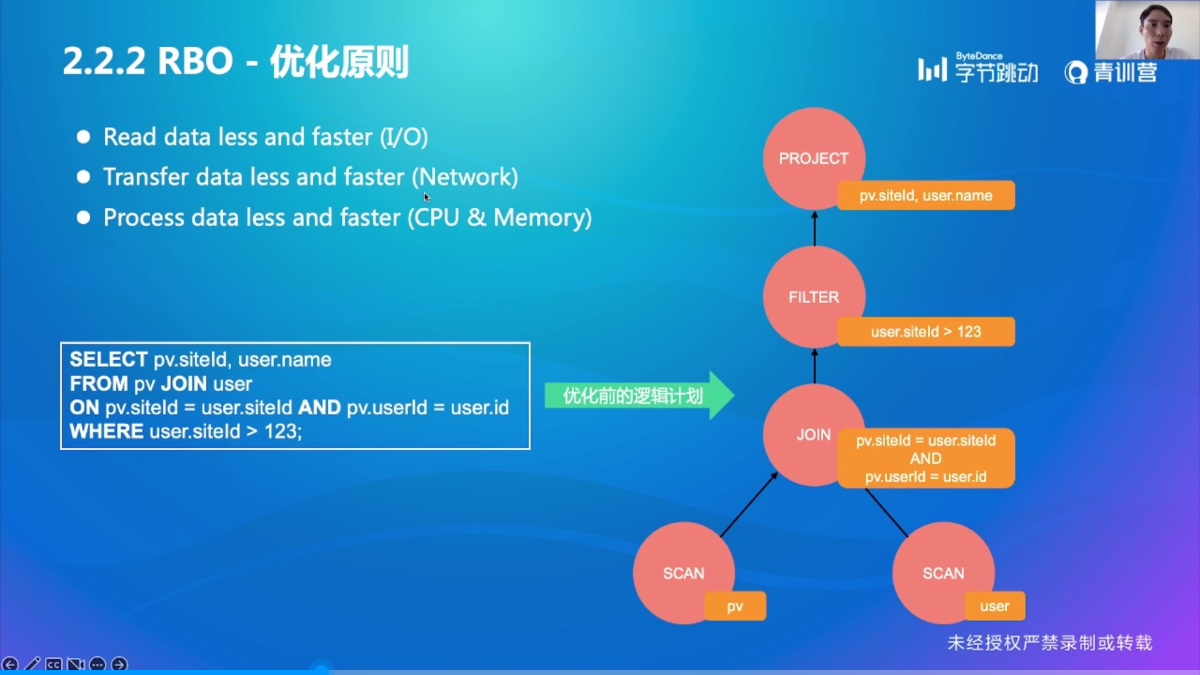
3 个优化原则
优化规则1:列裁剪
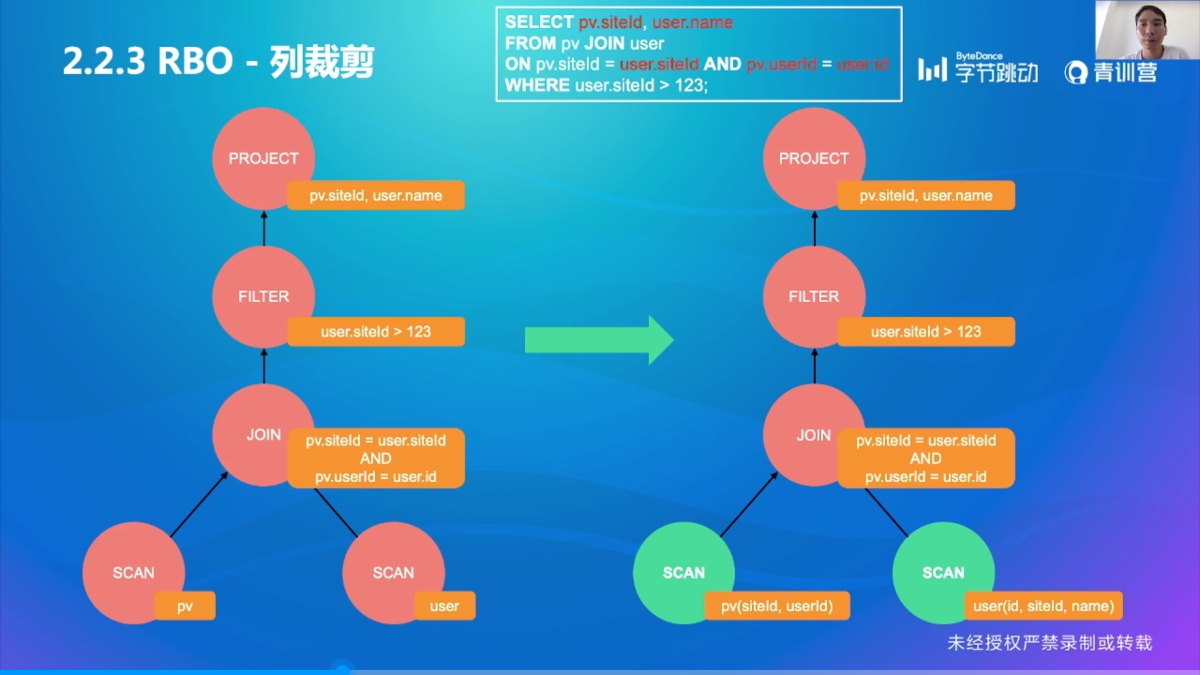
只读取需要的列
优化规则2:谓词下推
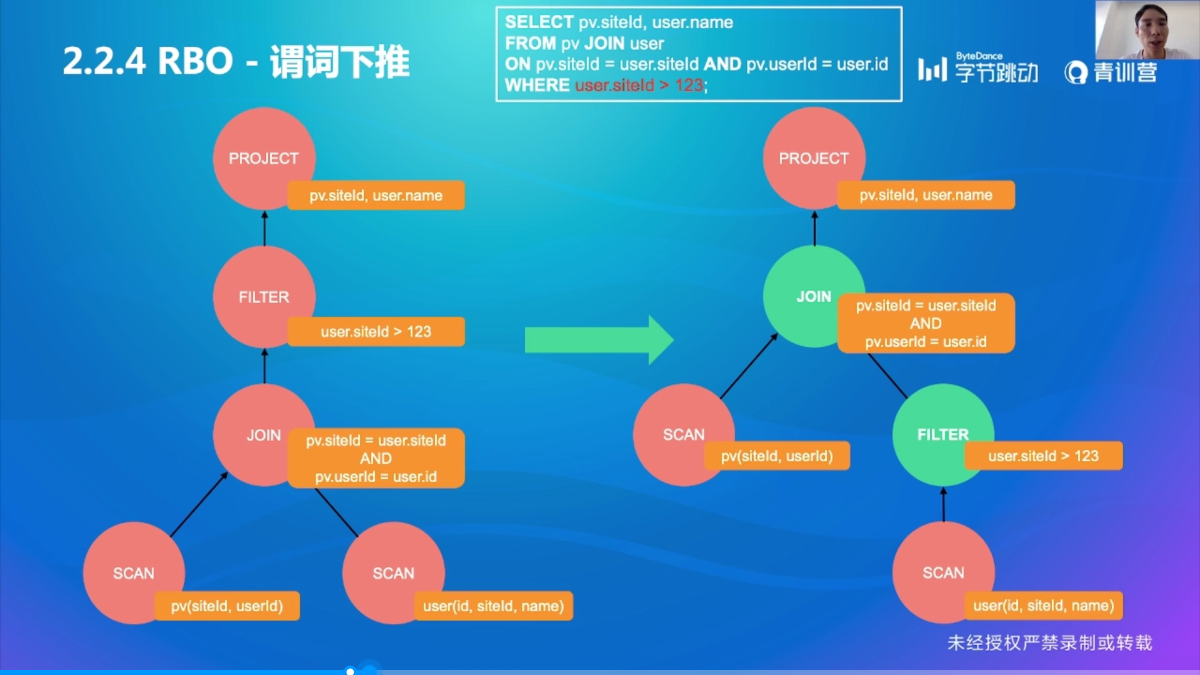
尽早过滤掉不必要的行,减少资源占用
优化规则3:传递闭包
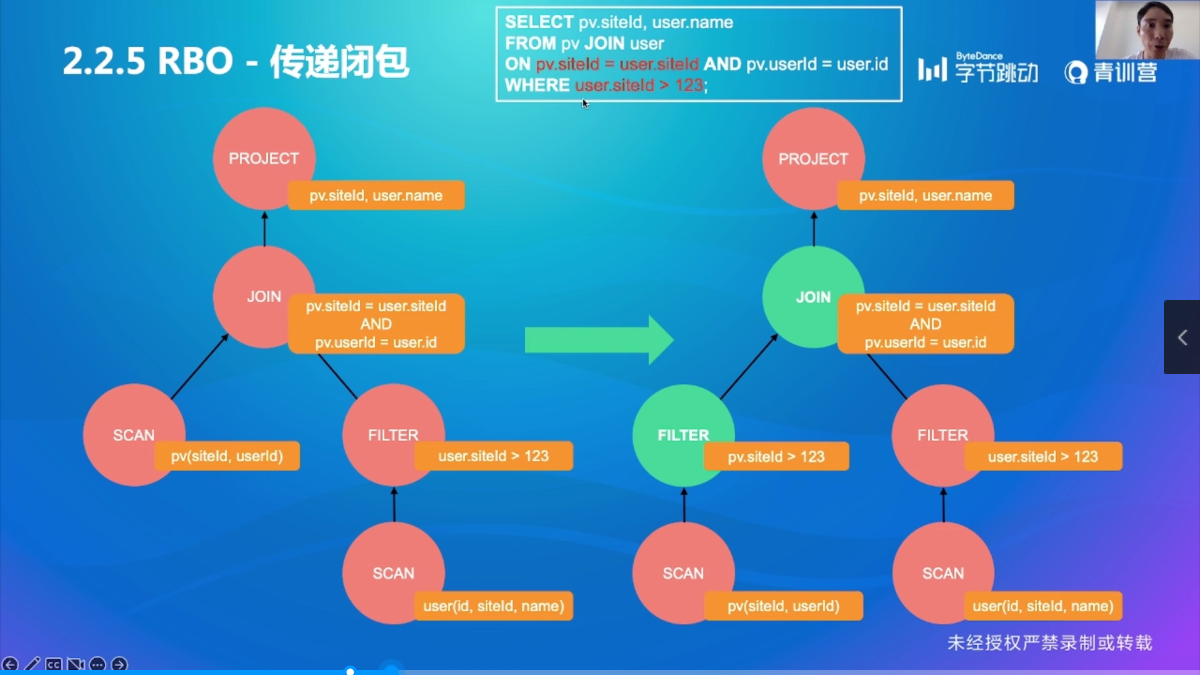
表达式的等值关系 + 过滤条件 = 新的过滤条件
优化规则4:Runtime Filter
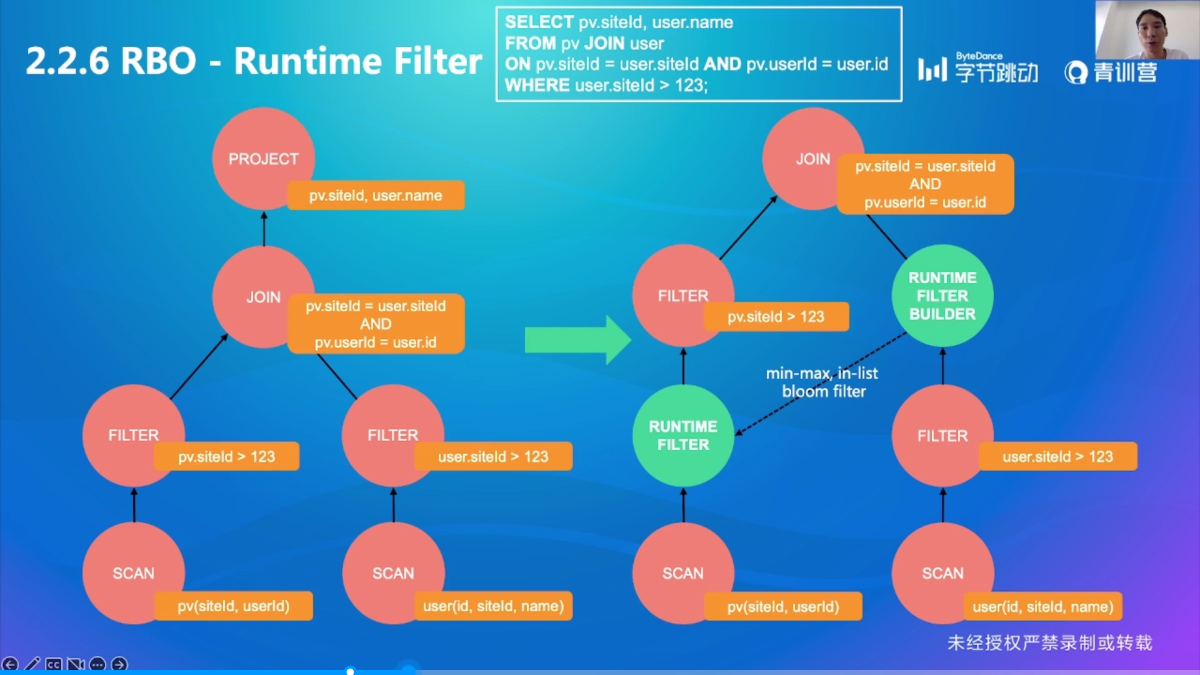
提早过滤左边的数据,那么就能减少开销(网络、运算等)
JOIN 的时候得到右侧 JOIN 集合的一些特性(例如知道右侧 JOIN KEY 的范围),然后通过这些特性先过滤左侧的数据
- min-max:知道了右侧的范围是 0~100,那么左侧就只扫描 0~100 的范围(缺点:范围必须是很紧密的,不然意义不大)
- in-list:如右侧的值很少,就可以使用 in-list ,使用集合包含过滤(缺点:右侧集合不能太大)
- bloom filter:通过右侧来构建,效果是给我一个数,如果说不在那就是不在,说在是有可能在(具体细节在后面的课程介绍)
RBO 小结

这里只讲了4 条经验规则,但一般实现都有几百条
优点是简单,但是缺点也很多(毕竟都是经验规则,不保证能得到最优的执行计划)
CBO(基于代价的优化)
概念
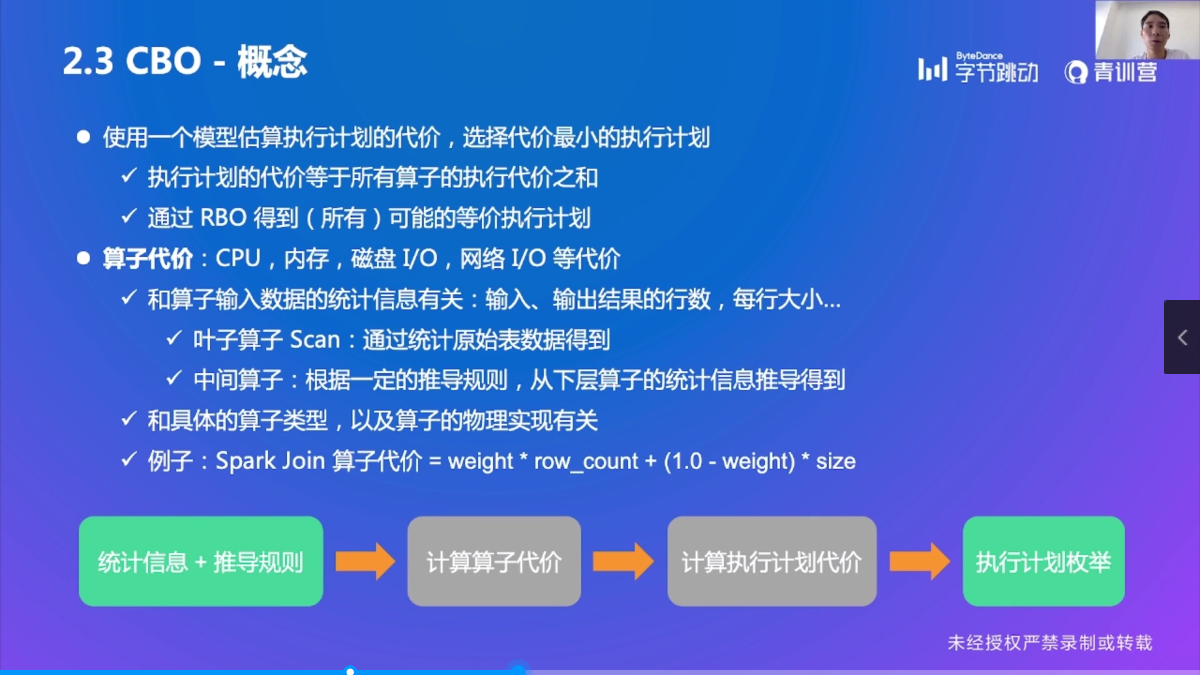
统计信息

统计信息的收集方式

统计信息推导规则
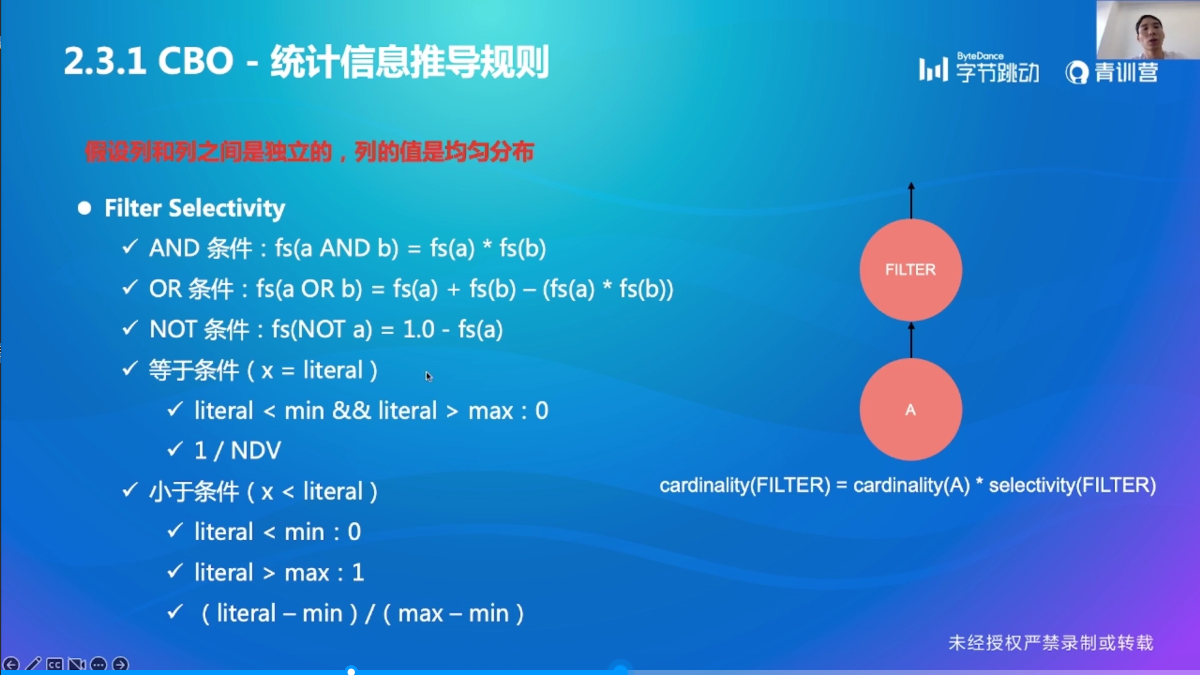
这个稍微看一下应该不难理解
统计信息的问题
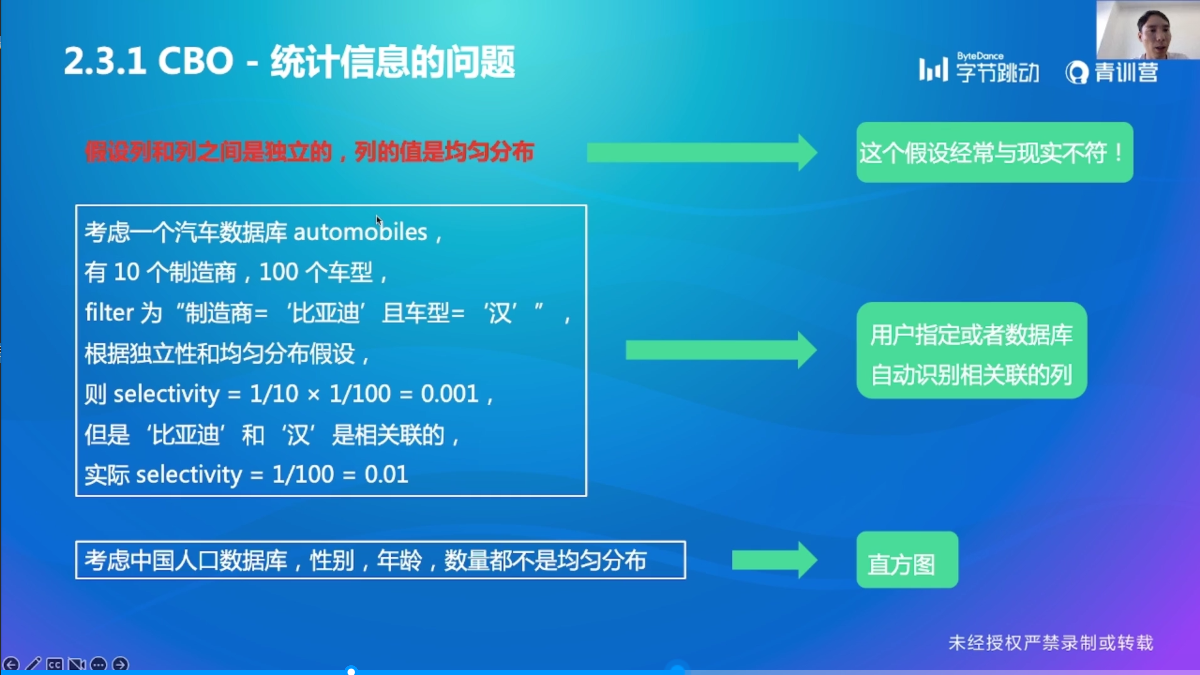
(如果是汉,那么必定是比亚迪的)
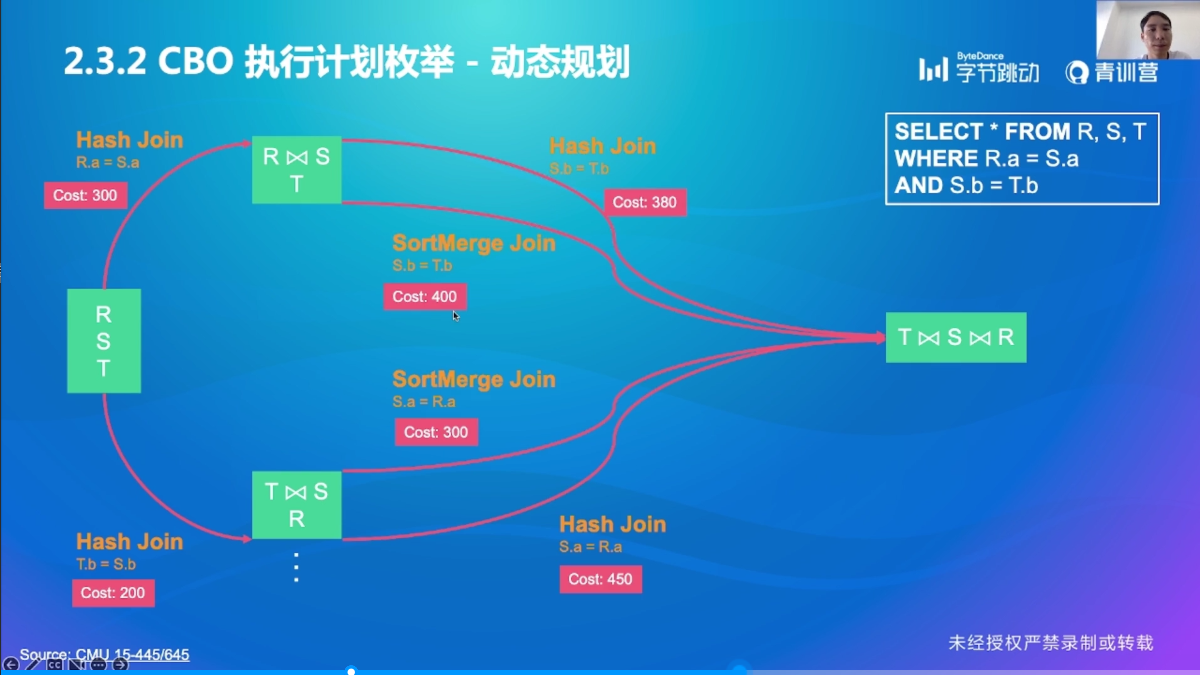
执行计划枚举


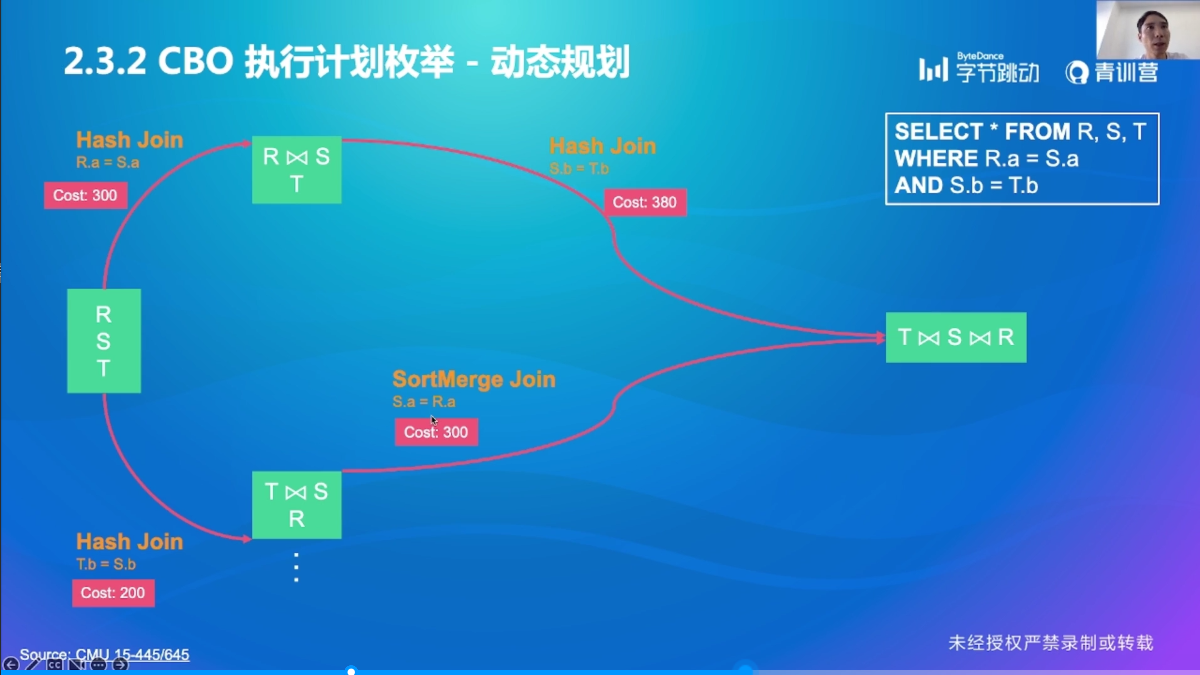
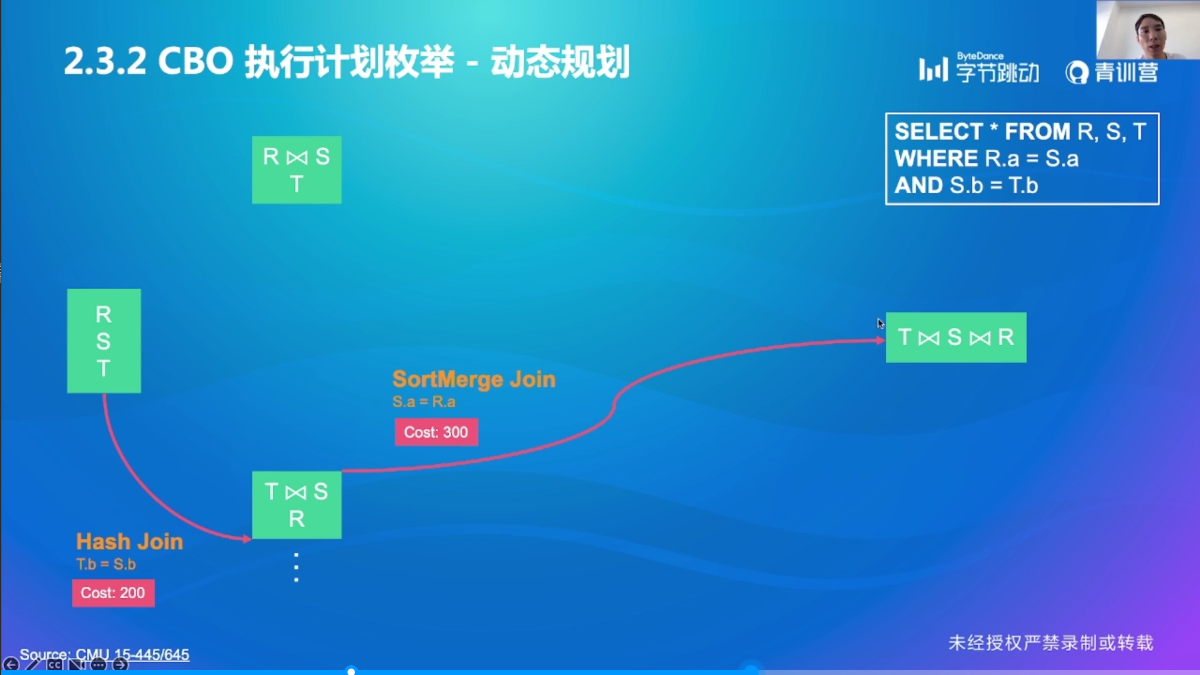
CBO 效果
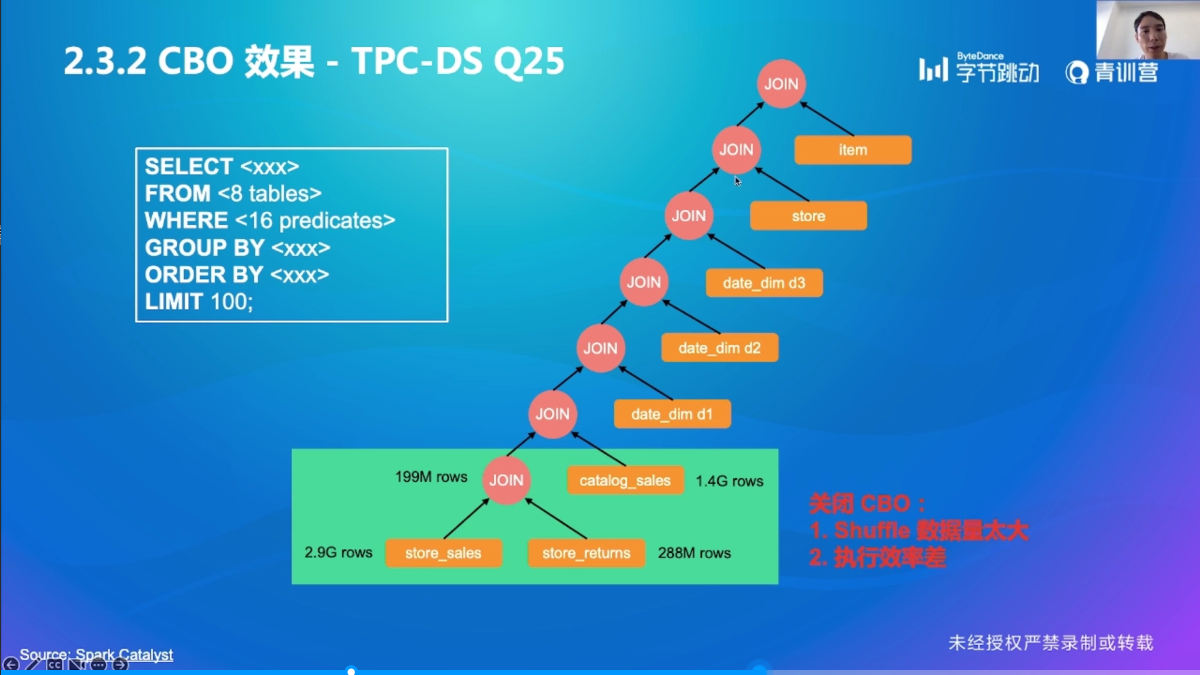
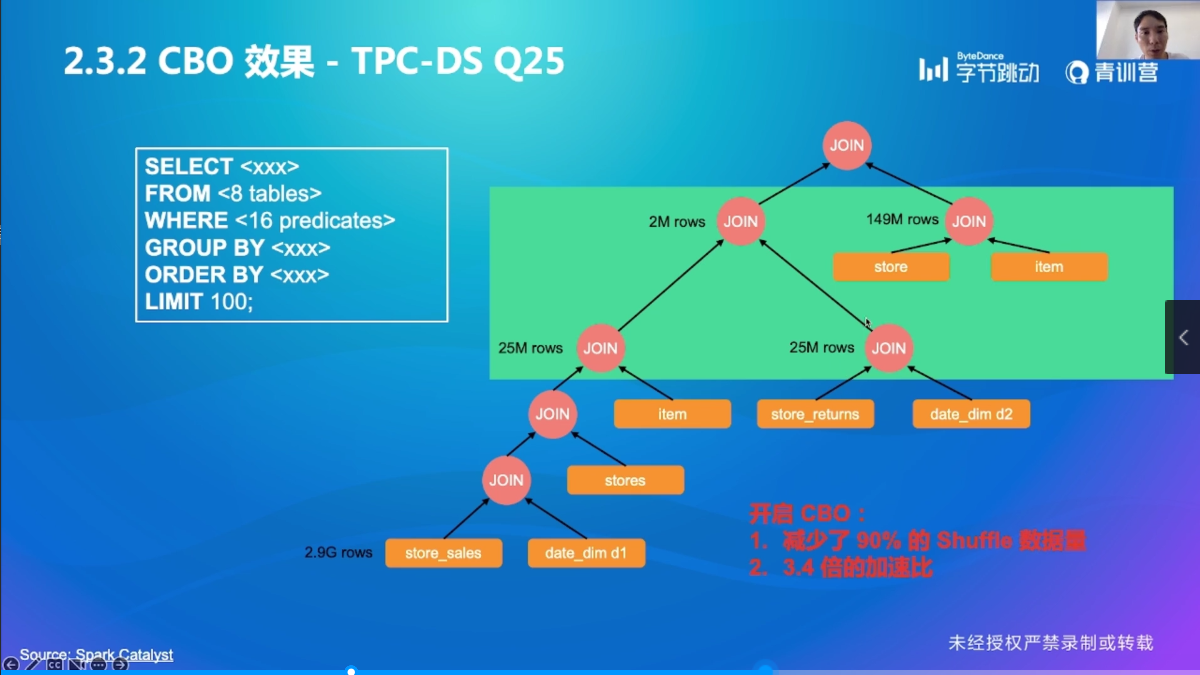
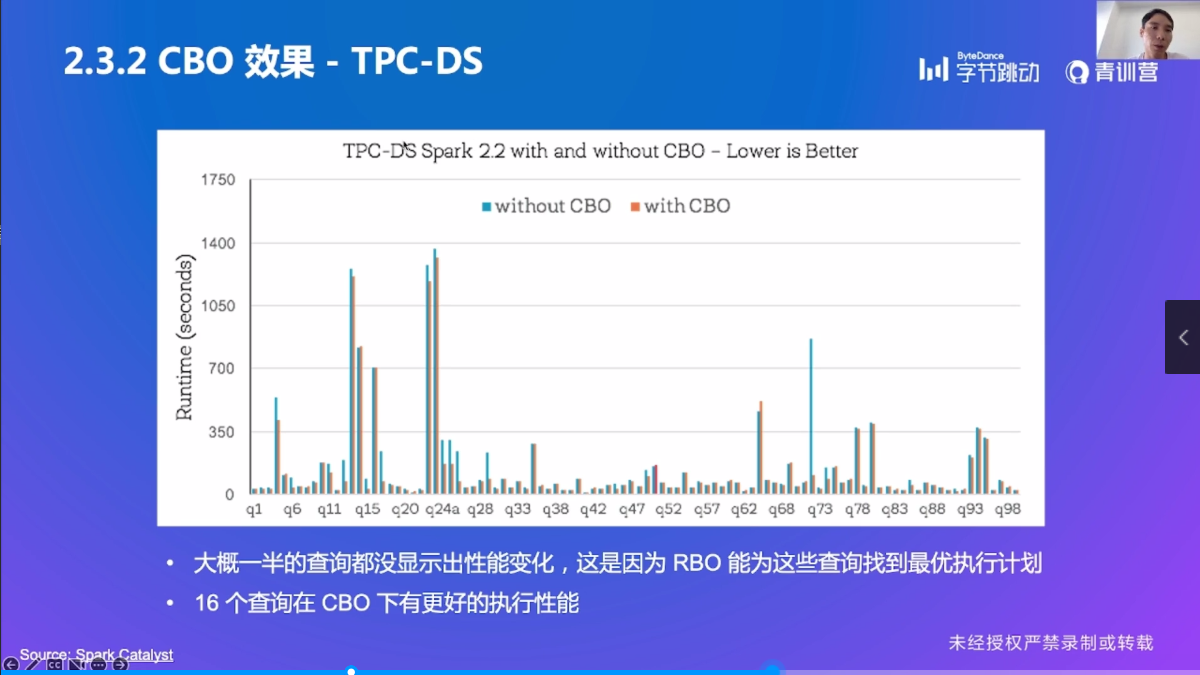
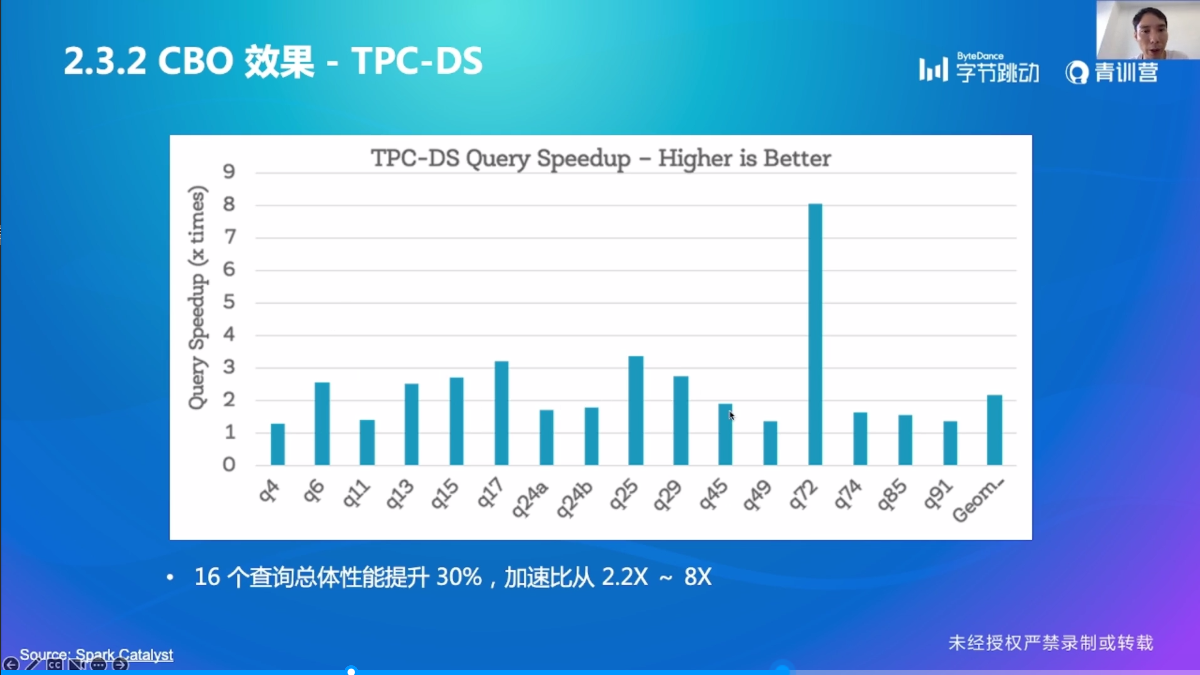
CBO 小结

小结

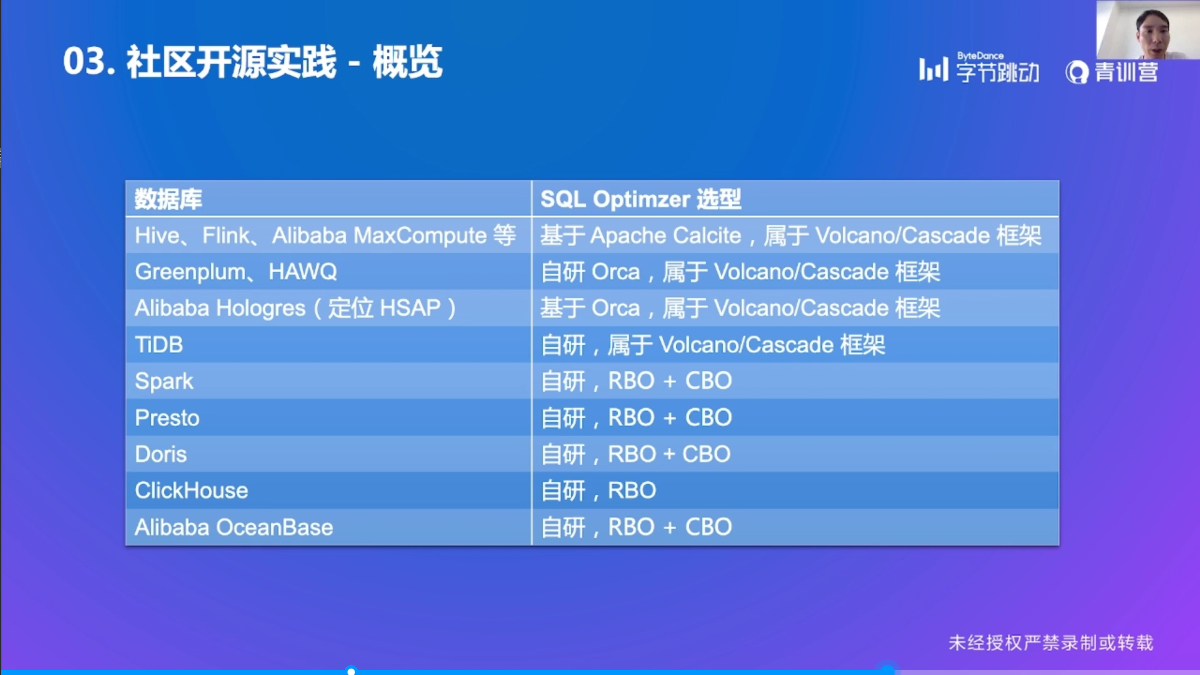
社区开源实践
概览
Apache Calcite
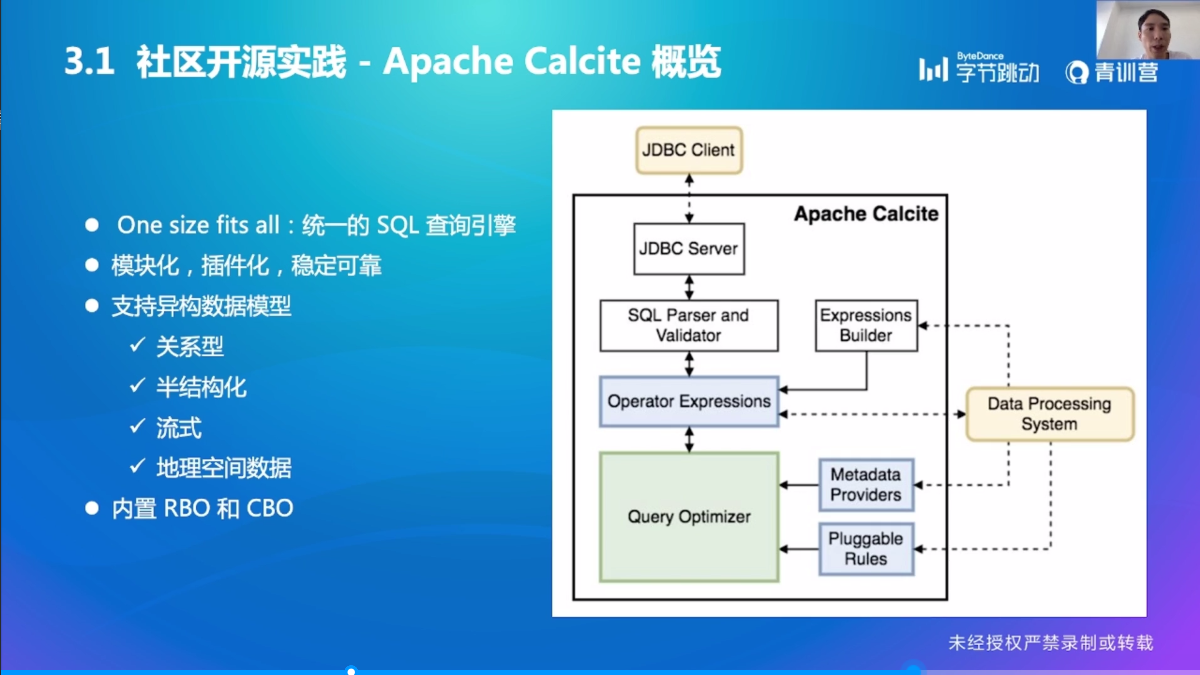
作为一个优化器,下面可以对接各种系统
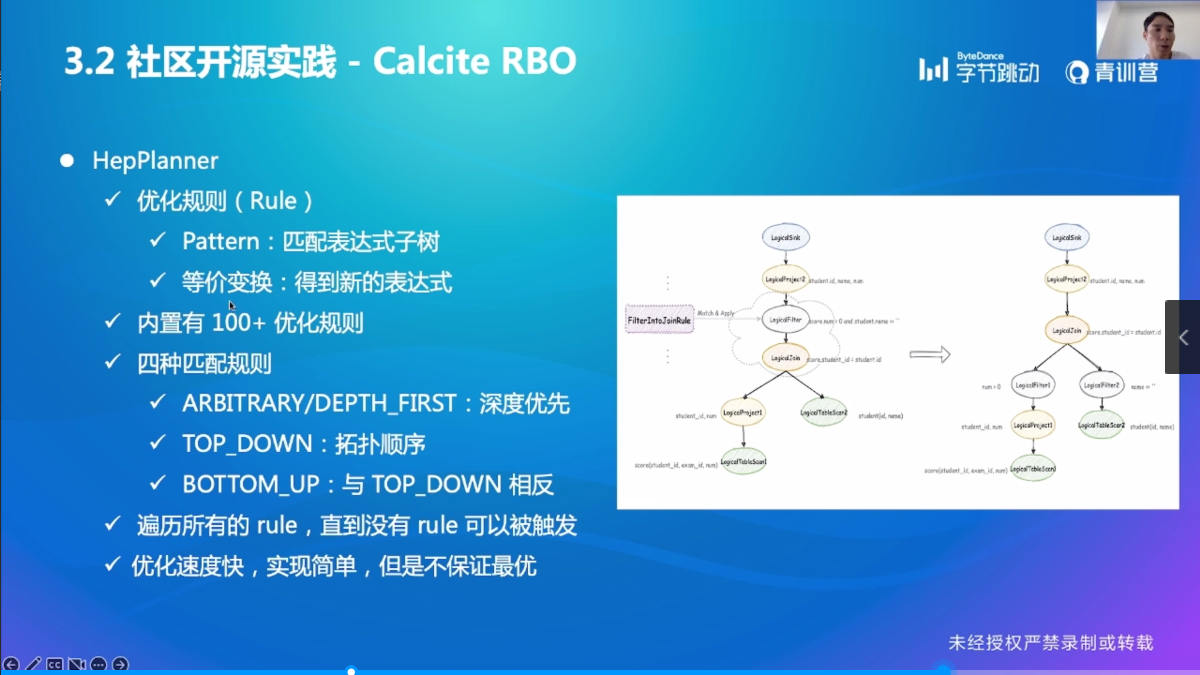
Calcite RBO
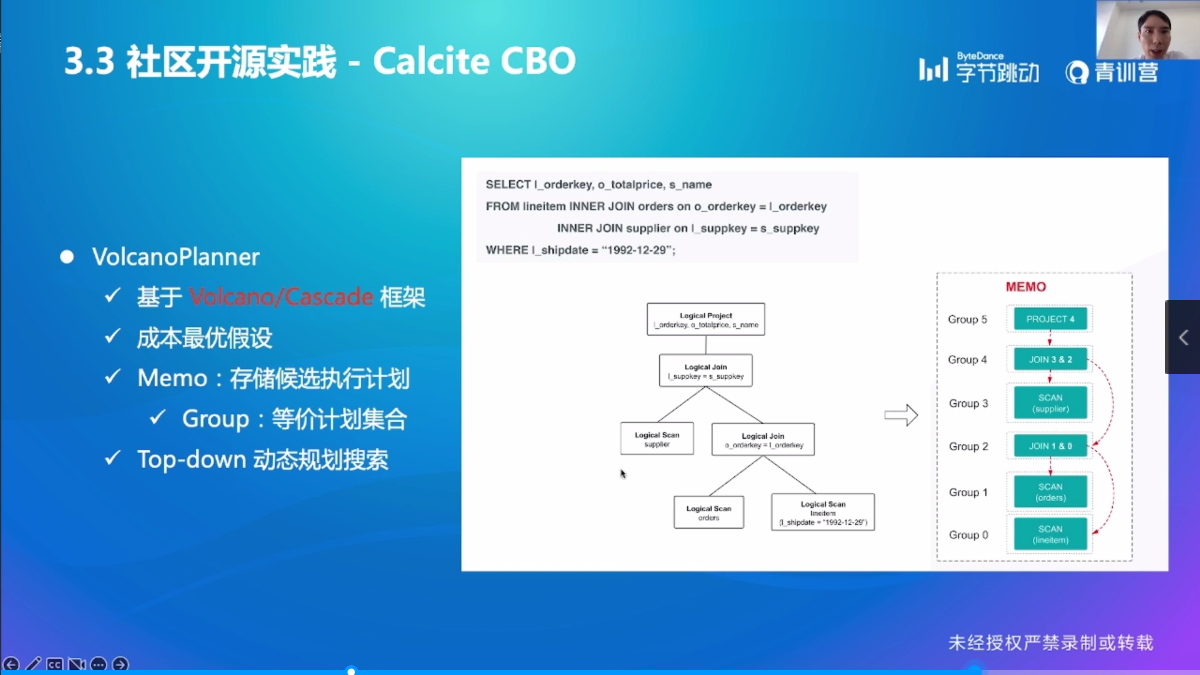
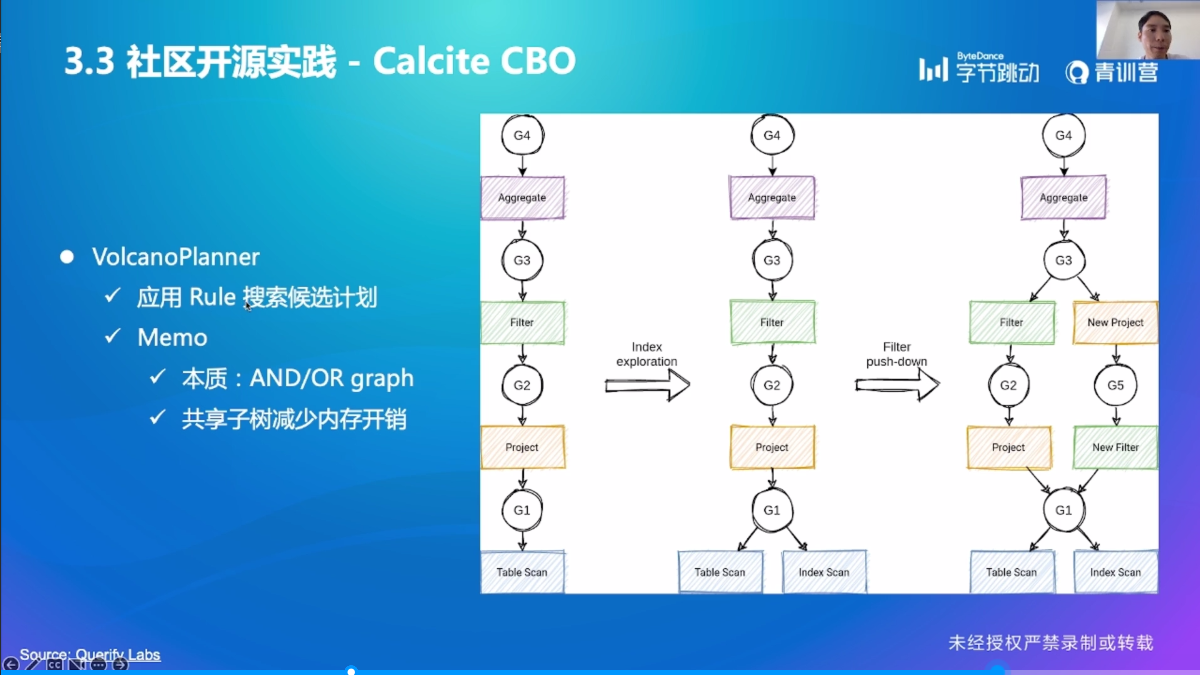
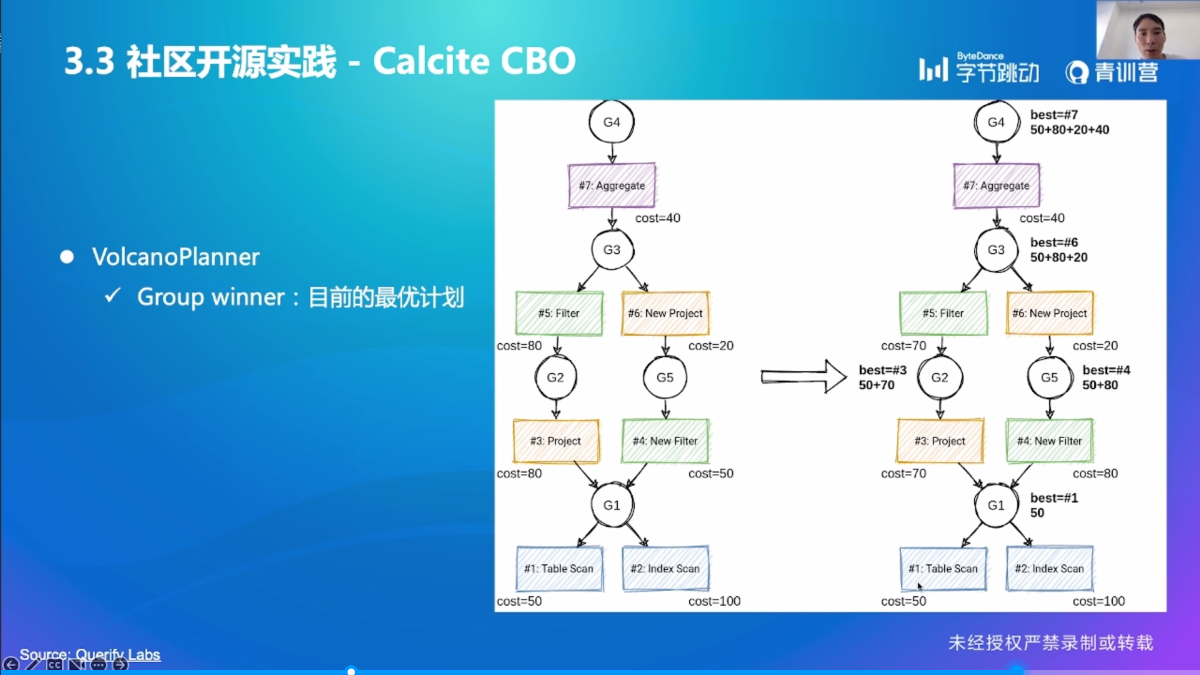
Calcite CBO
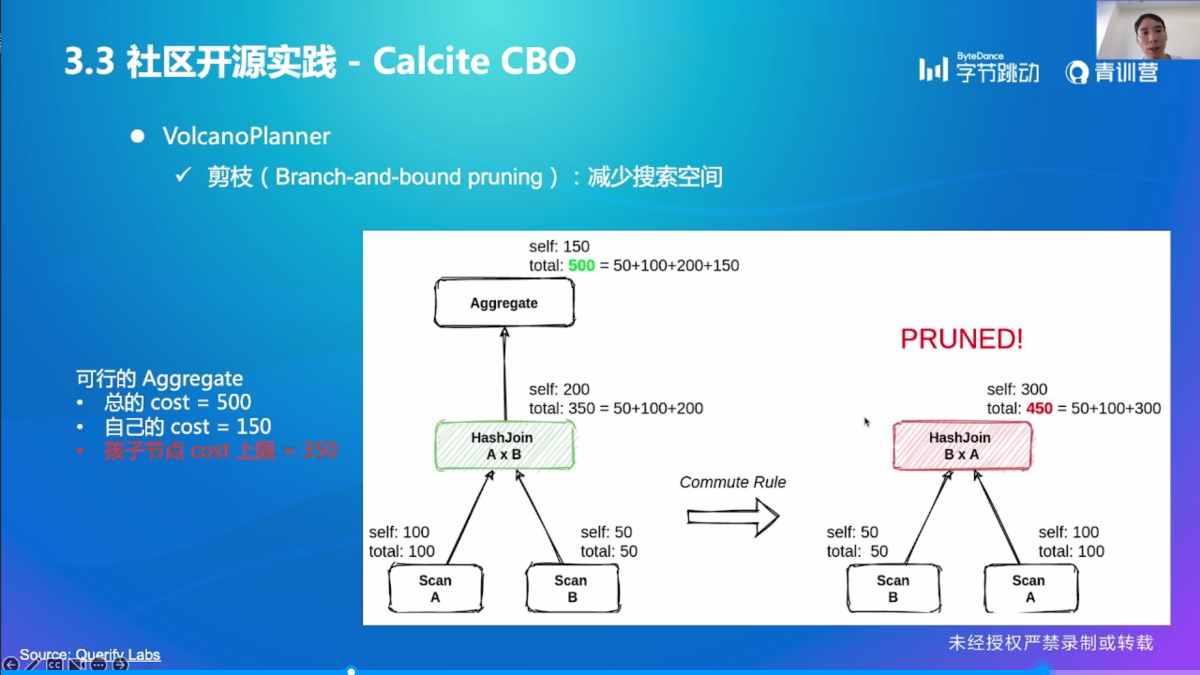
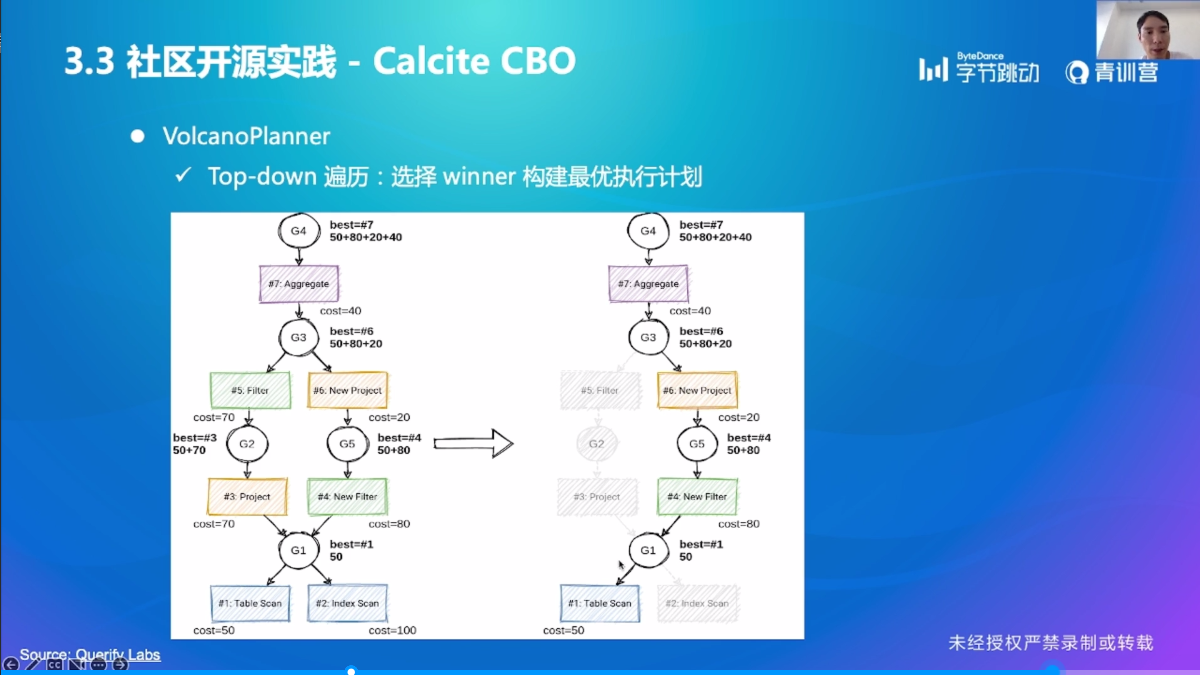
小结

前沿趋势
Big Data, Big Money

概览
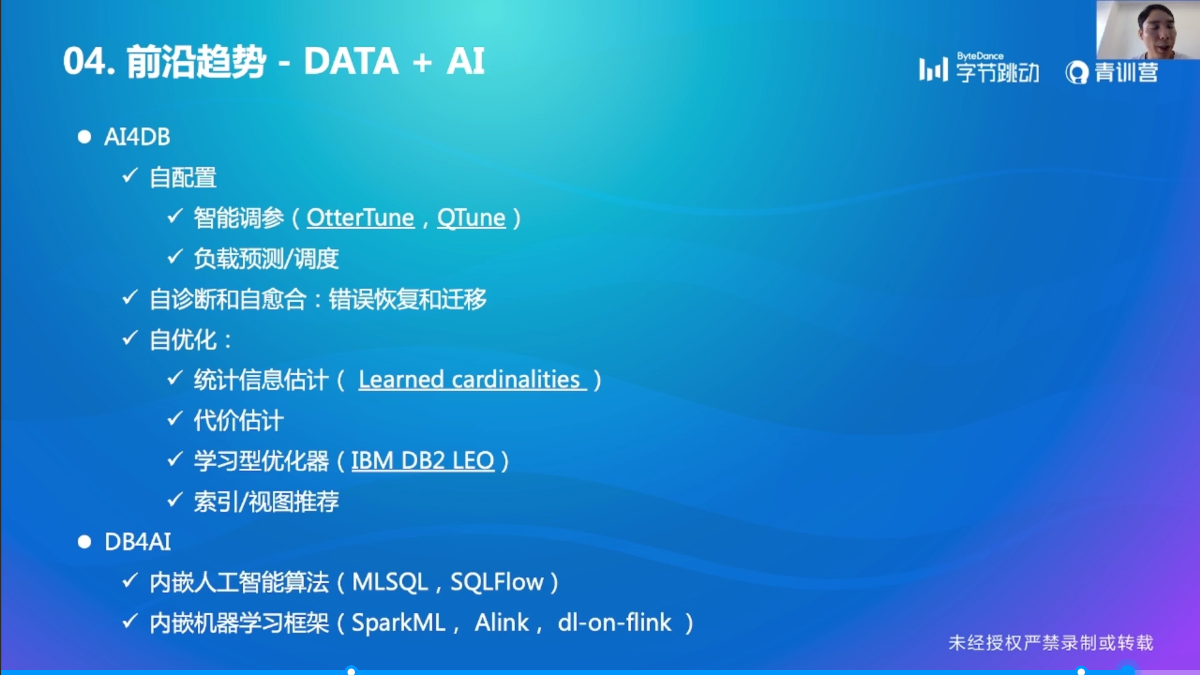
DATA + AI
小结

课程总结
评论
GiscusTwikoo