
『字节青训营-4th-大数据』L5:Spark 原理与实践
相关链接
🎶 学员手册:【大数据专场 学习资料二】第四届字节跳动青训营
大数据处理引擎 Spark
大数据处理技术栈

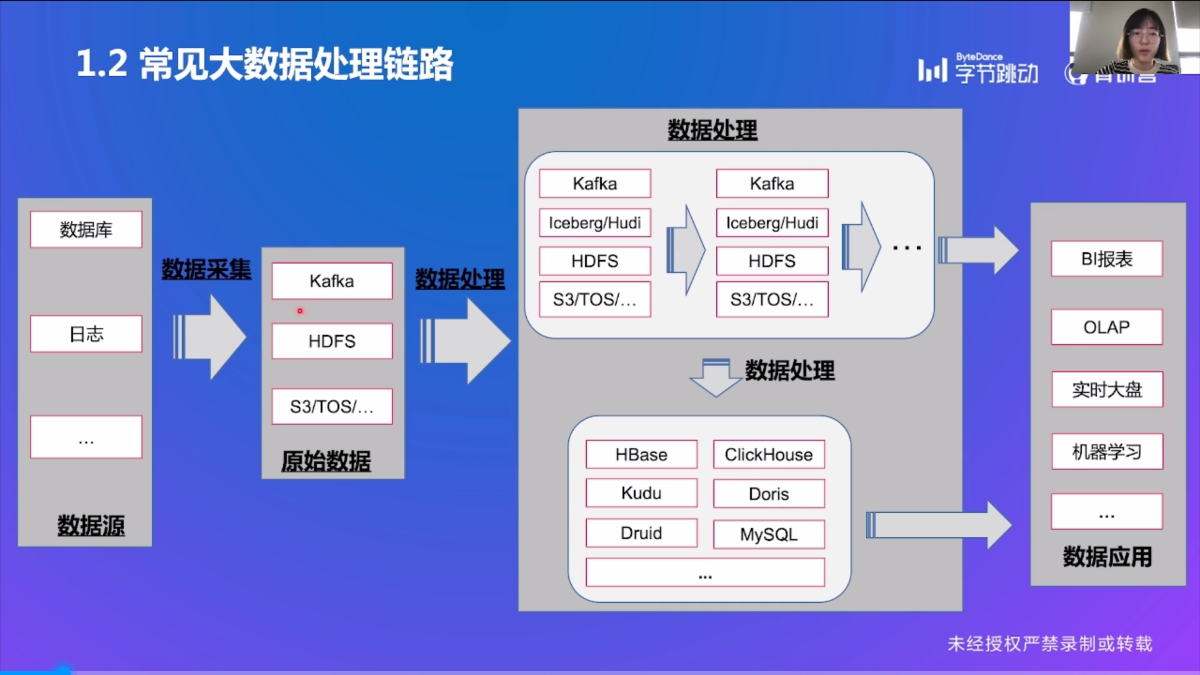
常见大数据处理链路
开源大数据处理引擎

什么是 Spark?

用于大规模数据处理的统一分析引擎
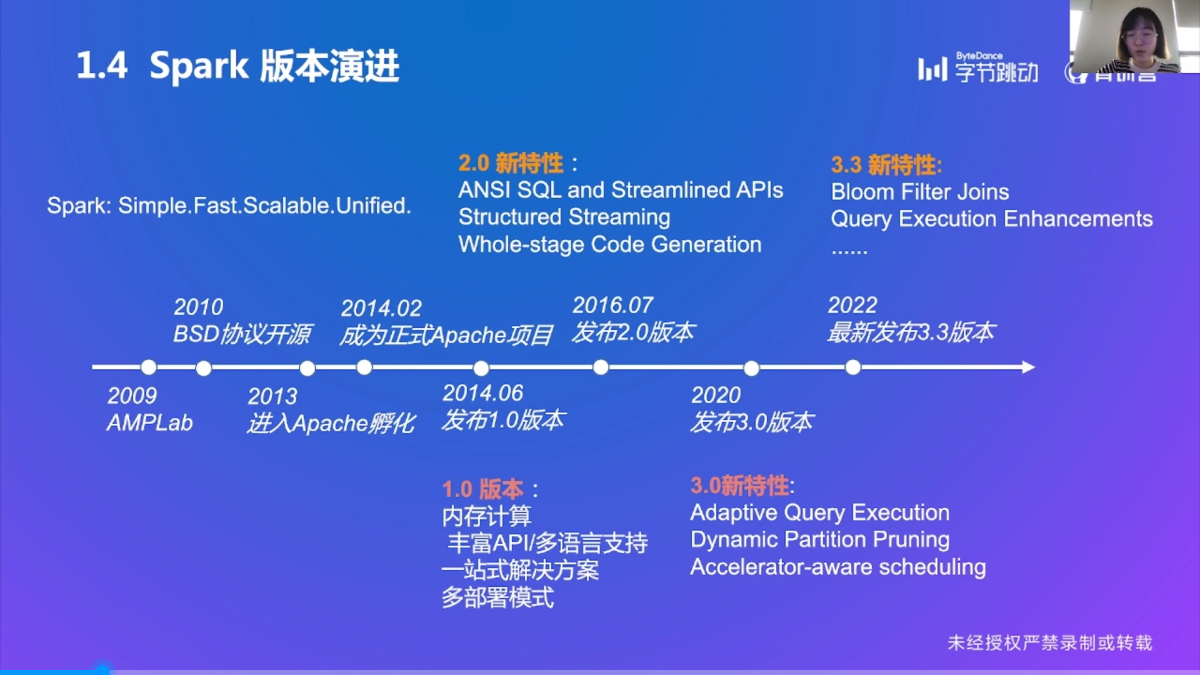
Spark 版本演进
Spark 生态 & 特点
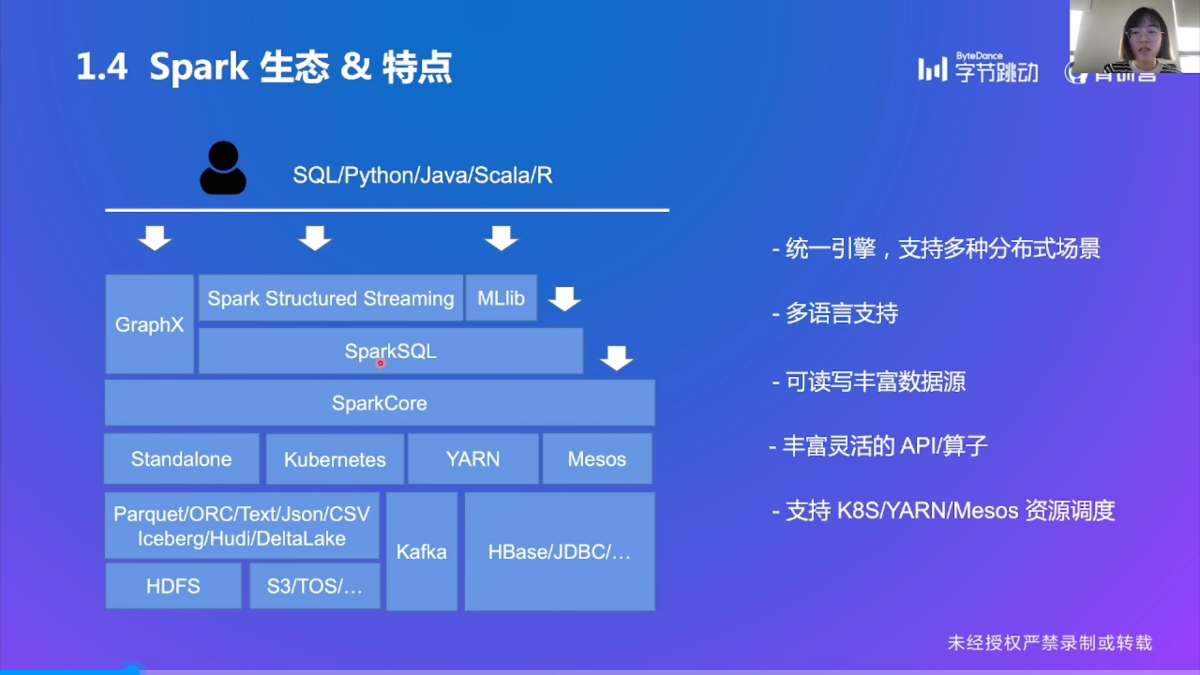
Spark 特点
多语言支持

丰富数据源

丰富的 API/算子

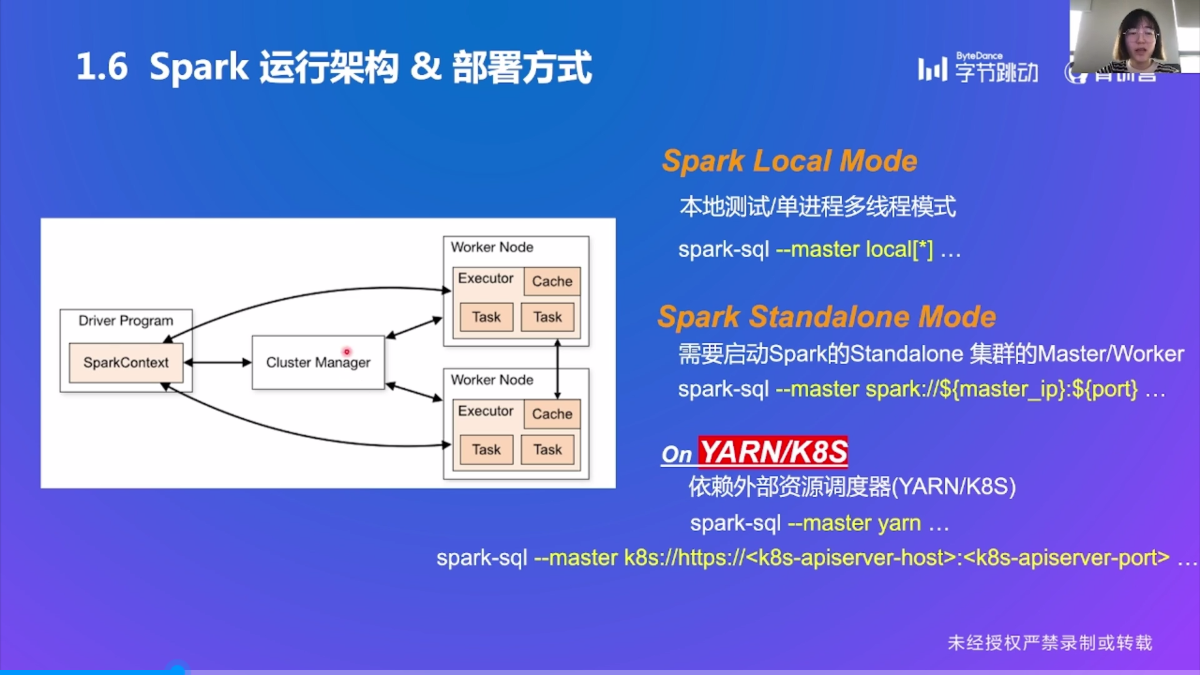
Spark 运行架构
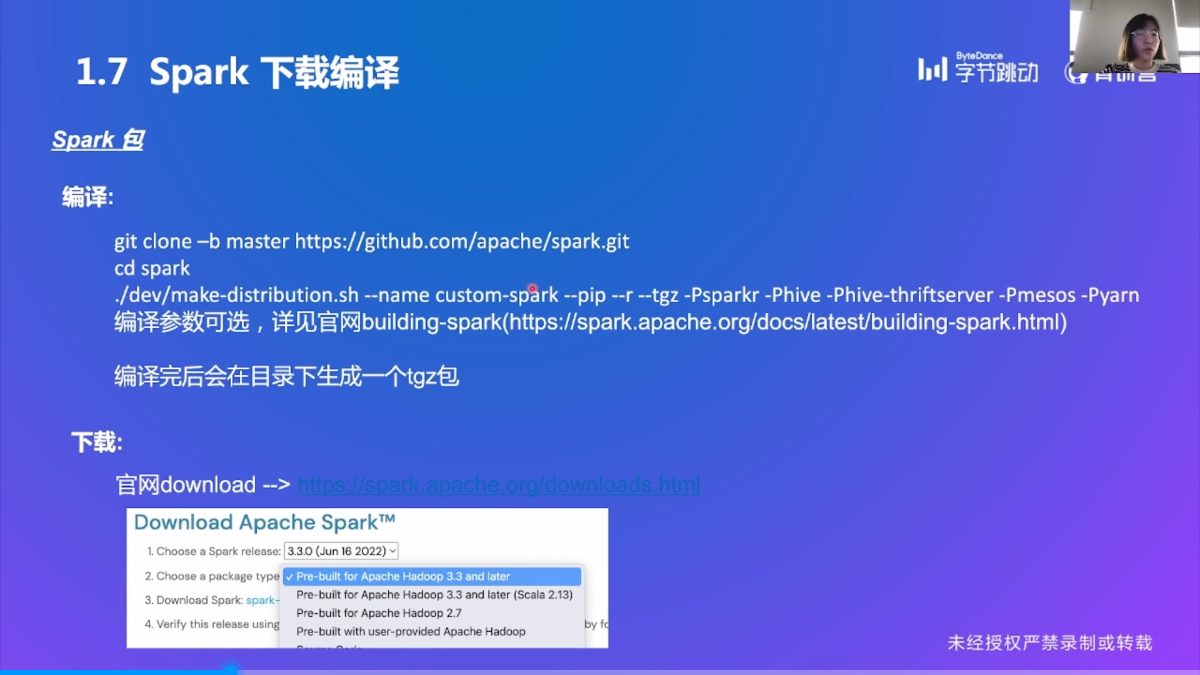
Spark 下载编译
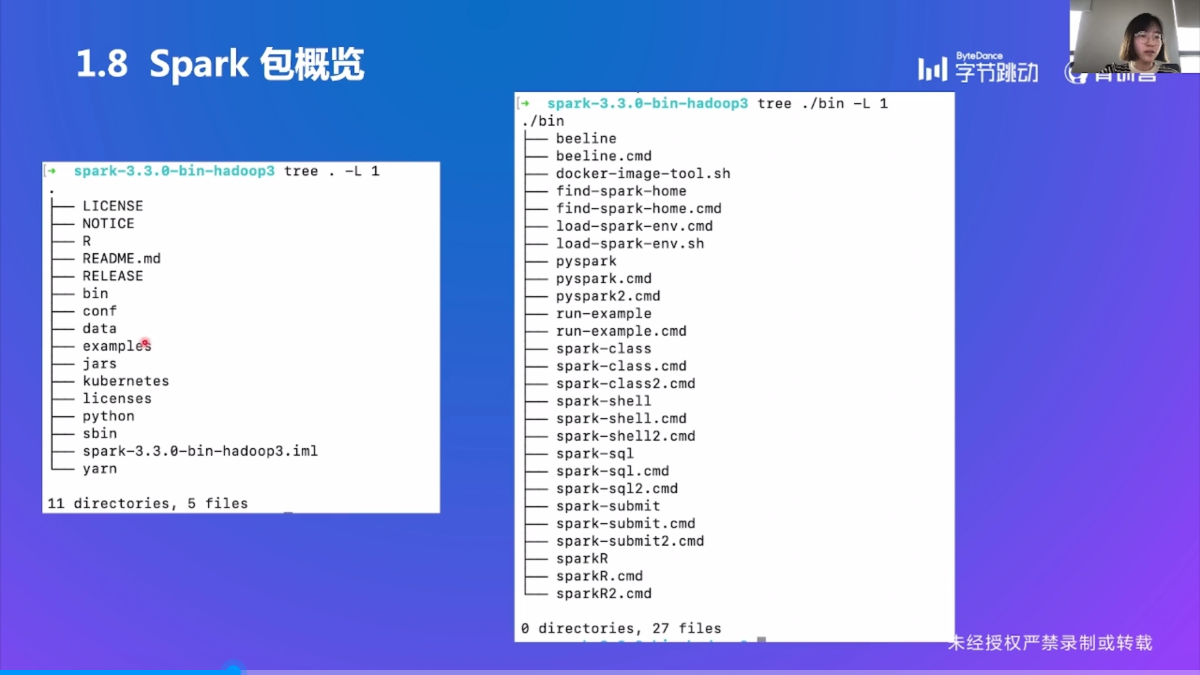
Spark 包概览
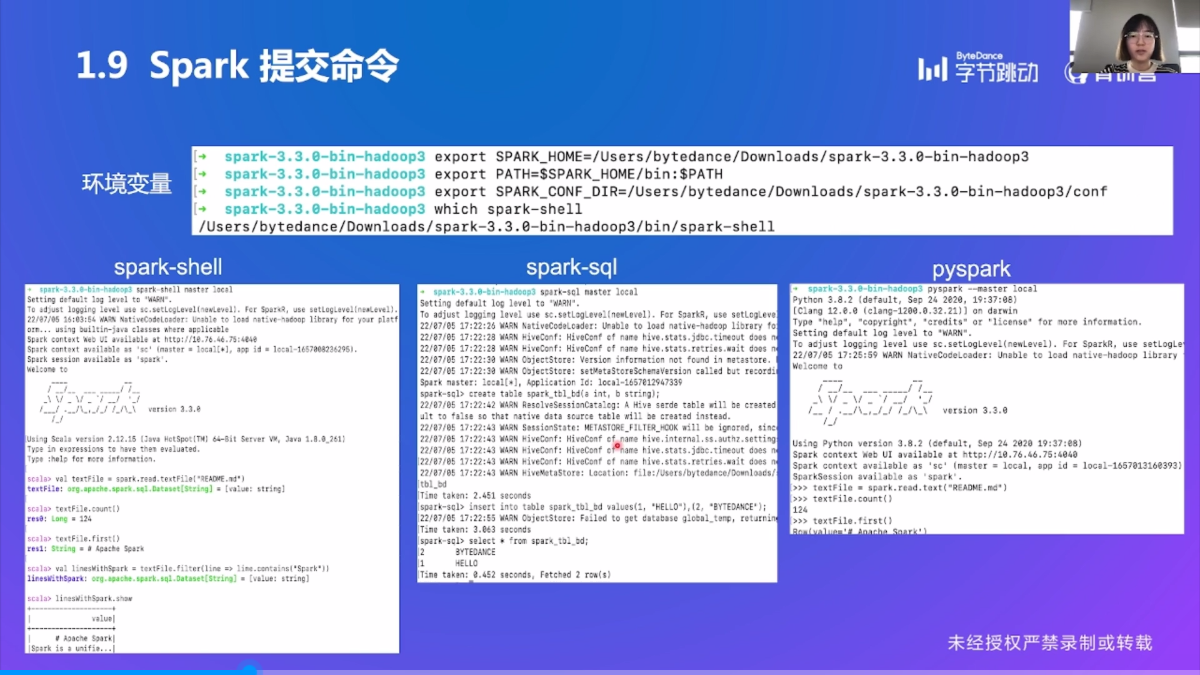
Spark 提交命令
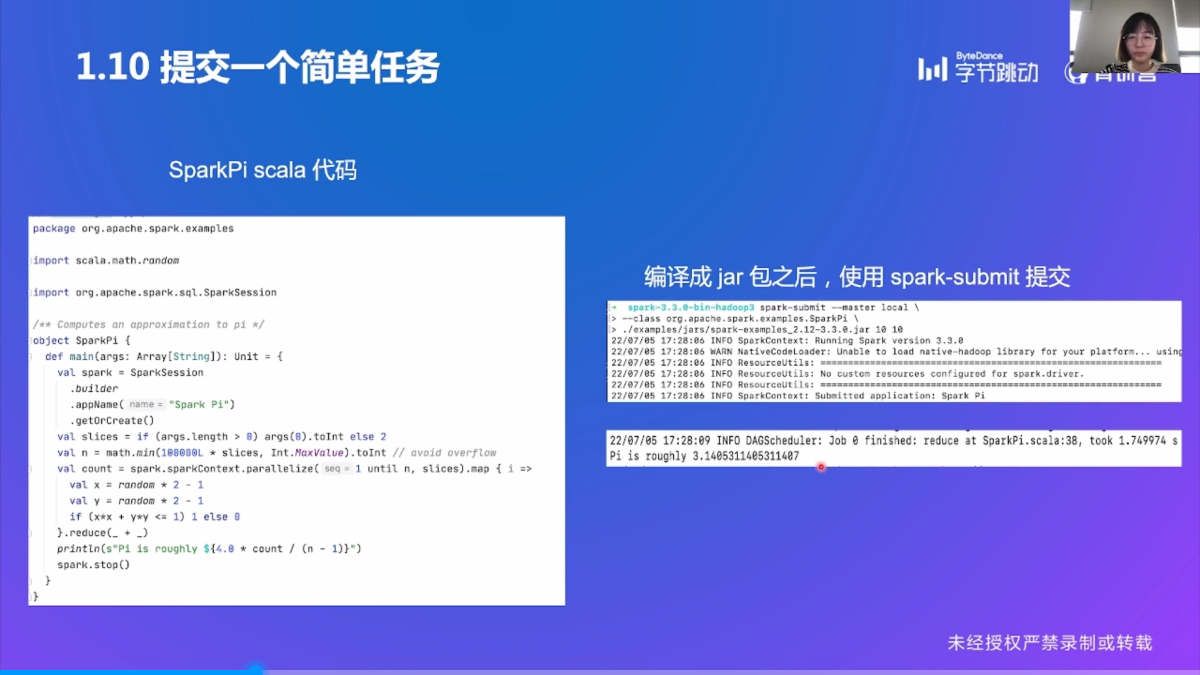
提交一个简单任务
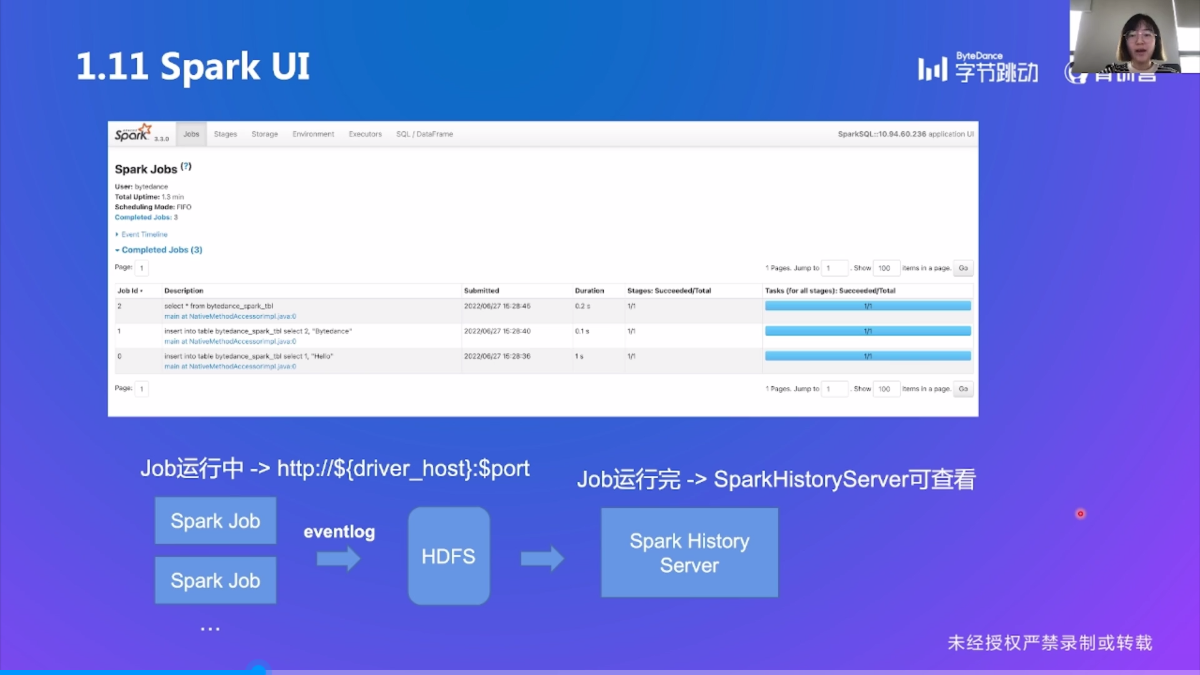
Spark UI
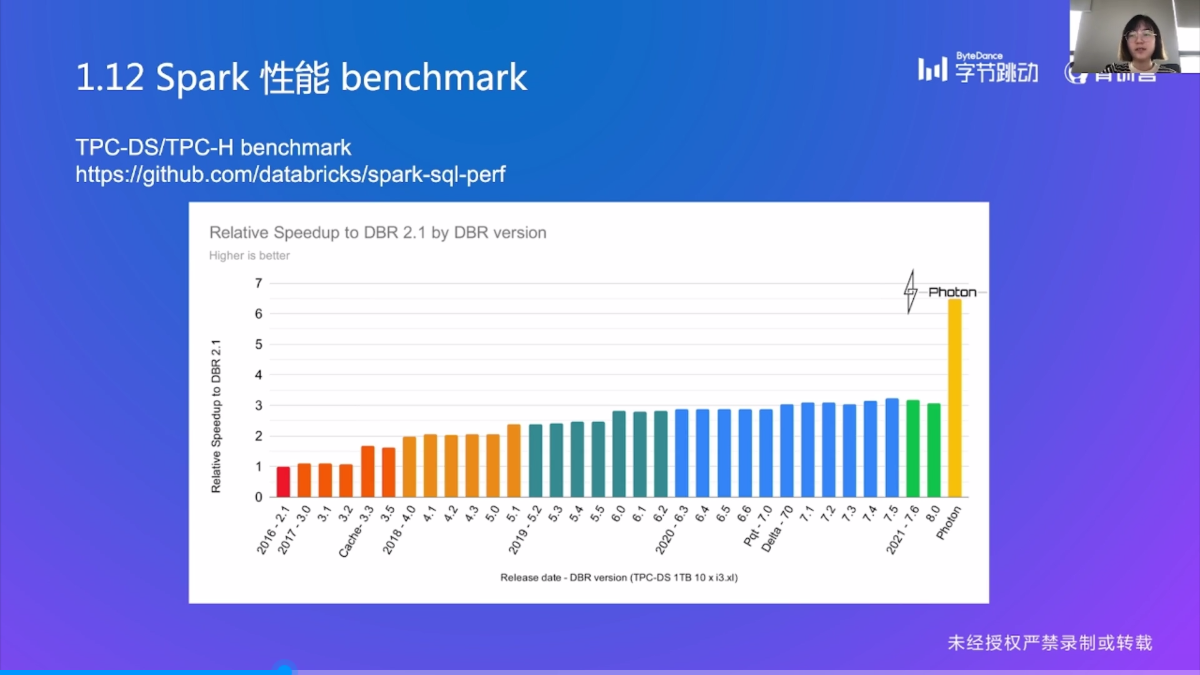
Spark 性能 benchmark
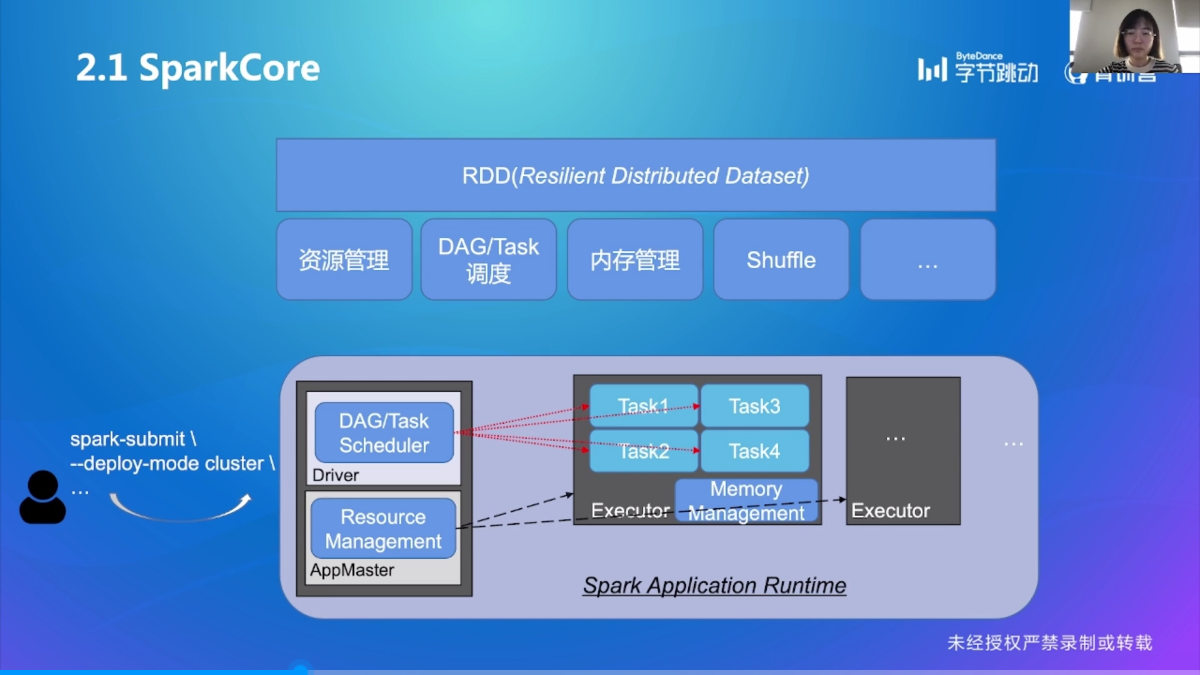
SparkCore 原理解析
SparkCore
什么是 RDD

一个容错的可以并行执行的分布式处理集
如何创建 RDD

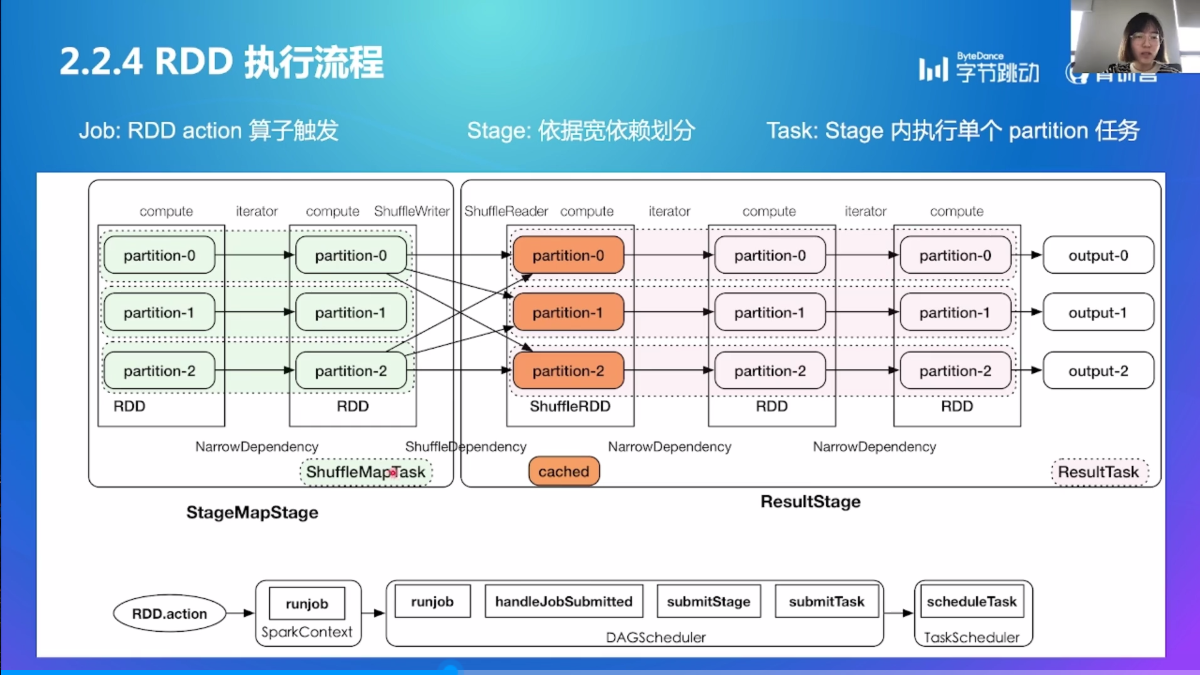
RDD 算子

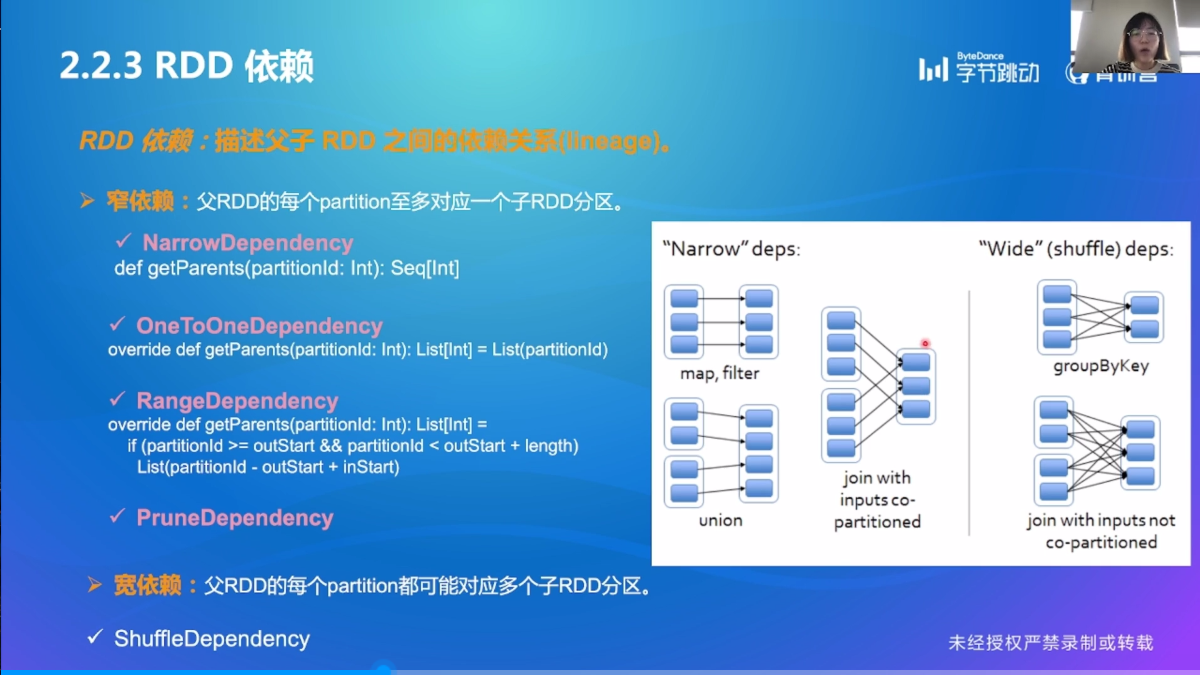
RDD 依赖

RDD 执行流程
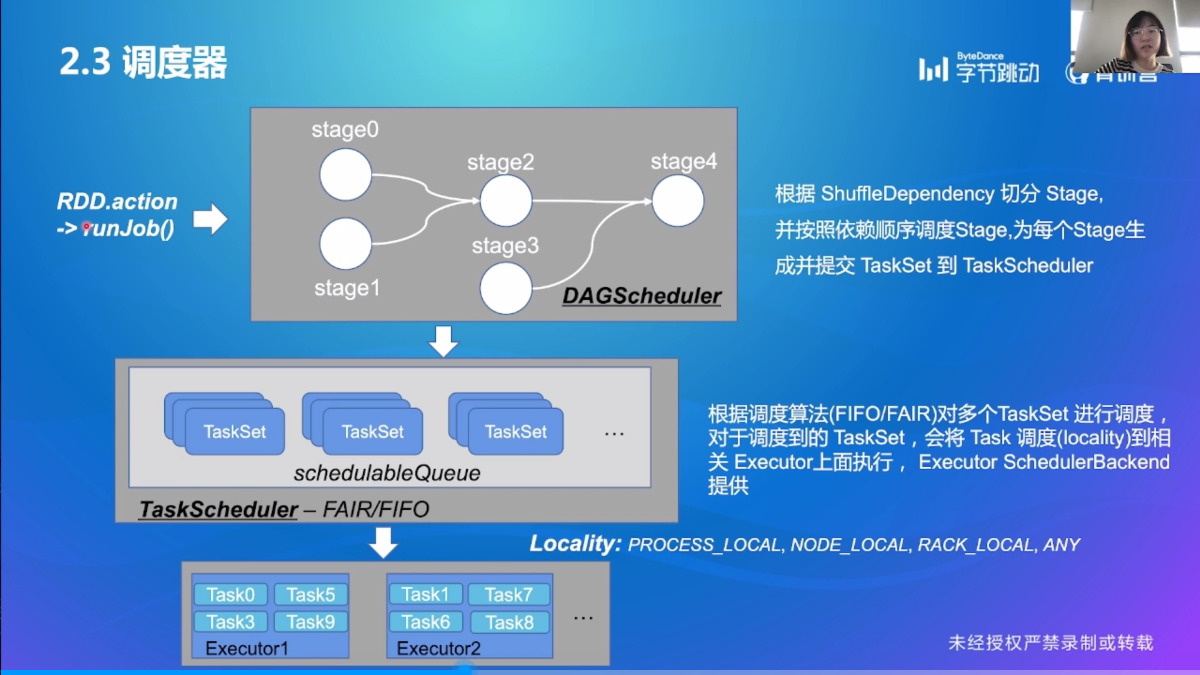
调度器
内存管理

多任务间内存分配

Shuffle
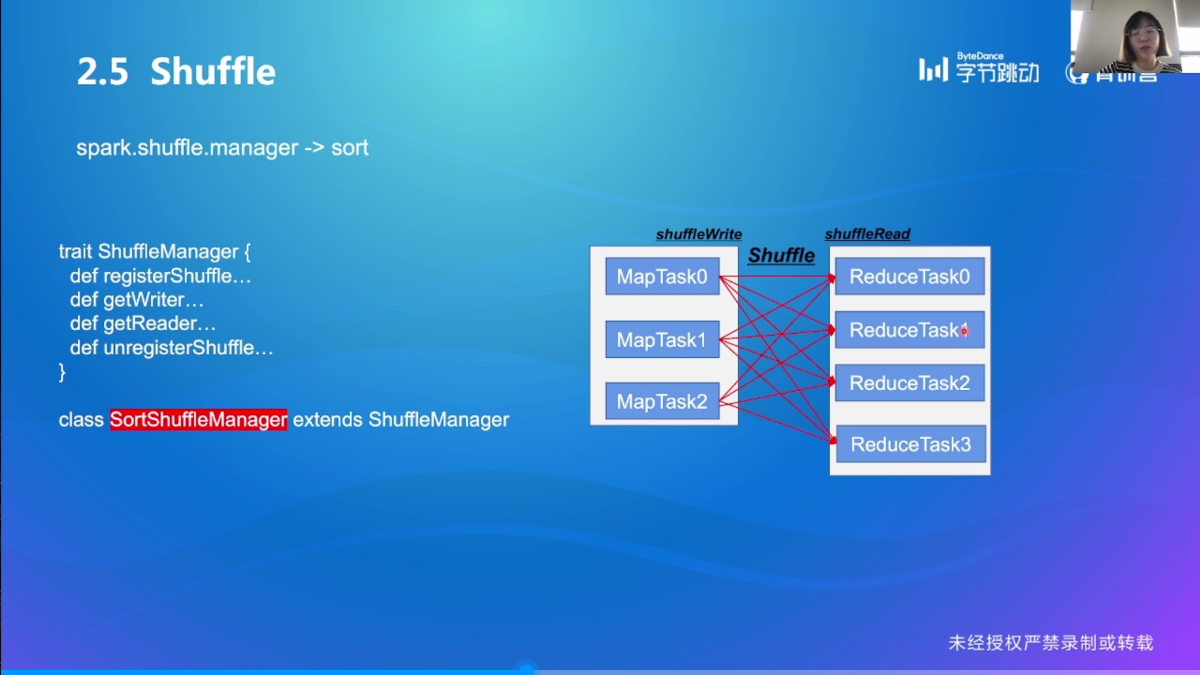
SortShuffleManager

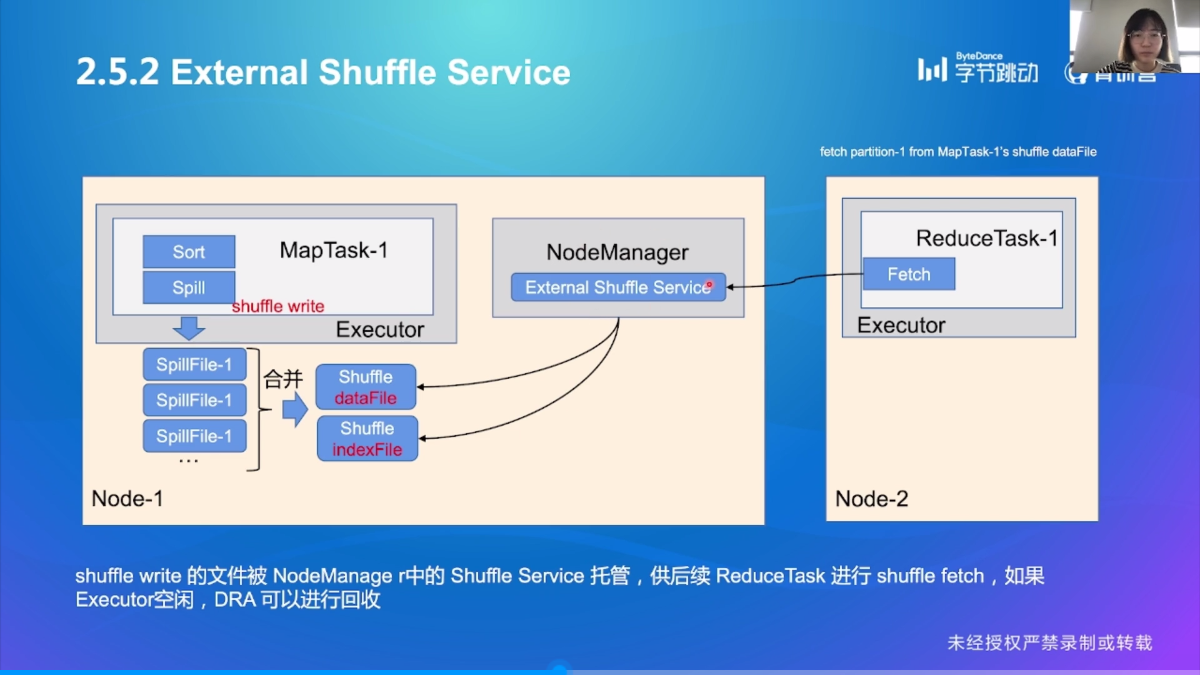
External Shuffle Service
SparkSQL 原理解析
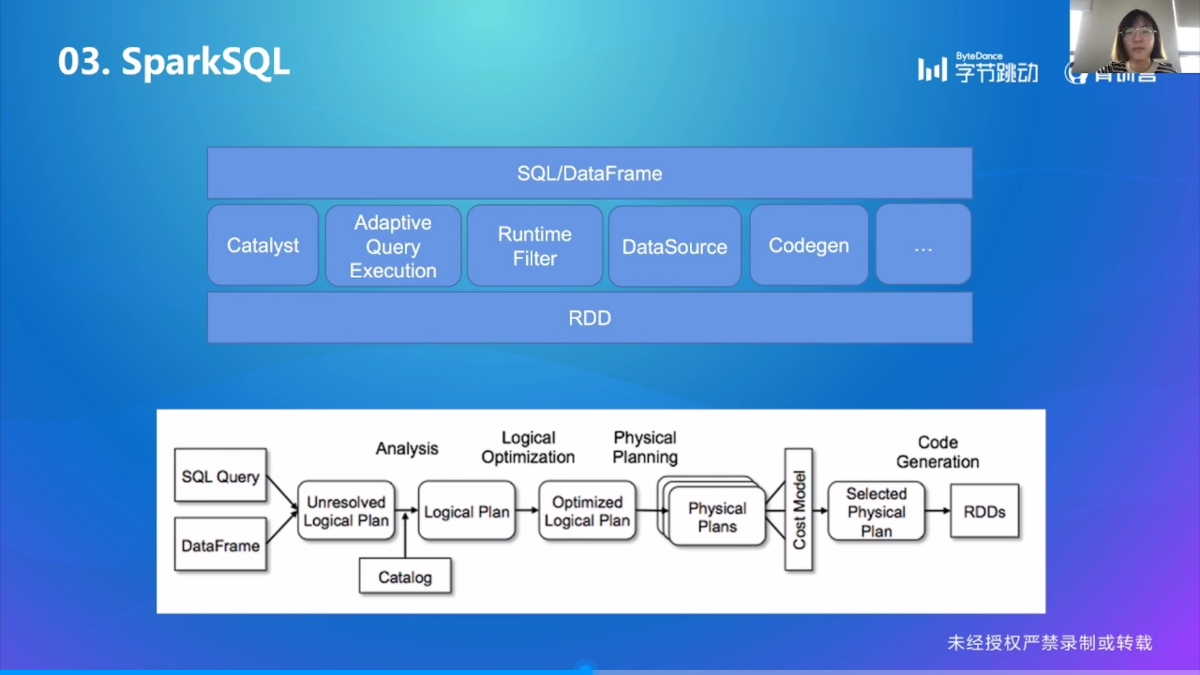
这里就是第一节课的内容了
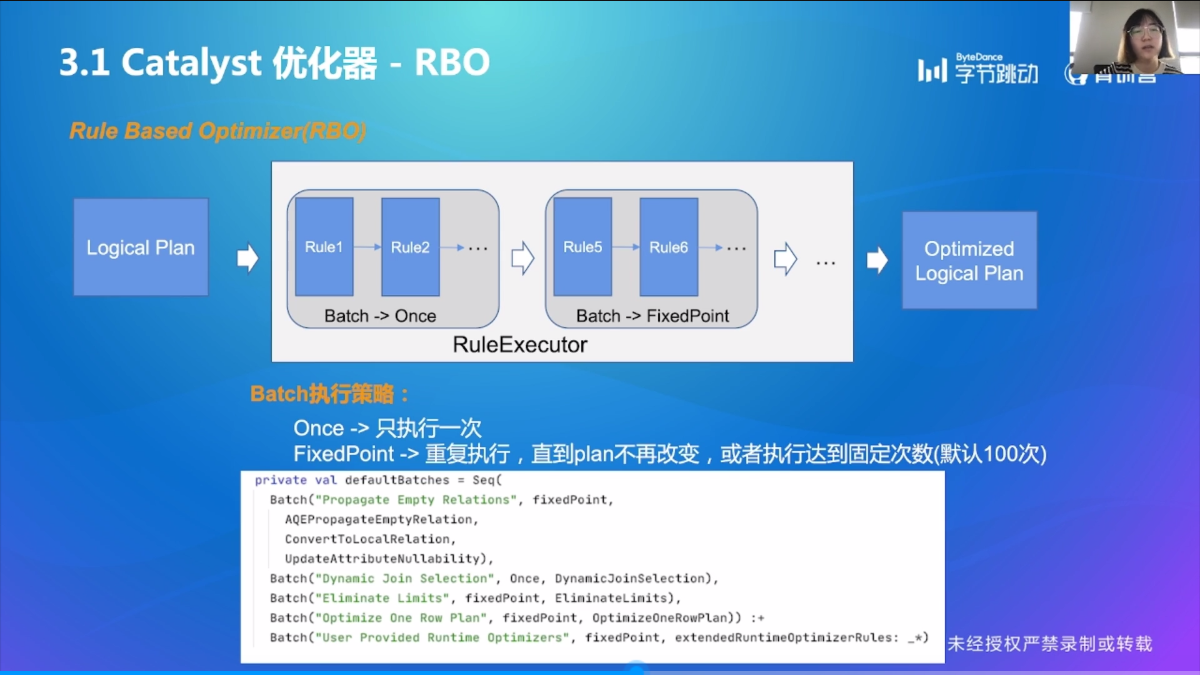
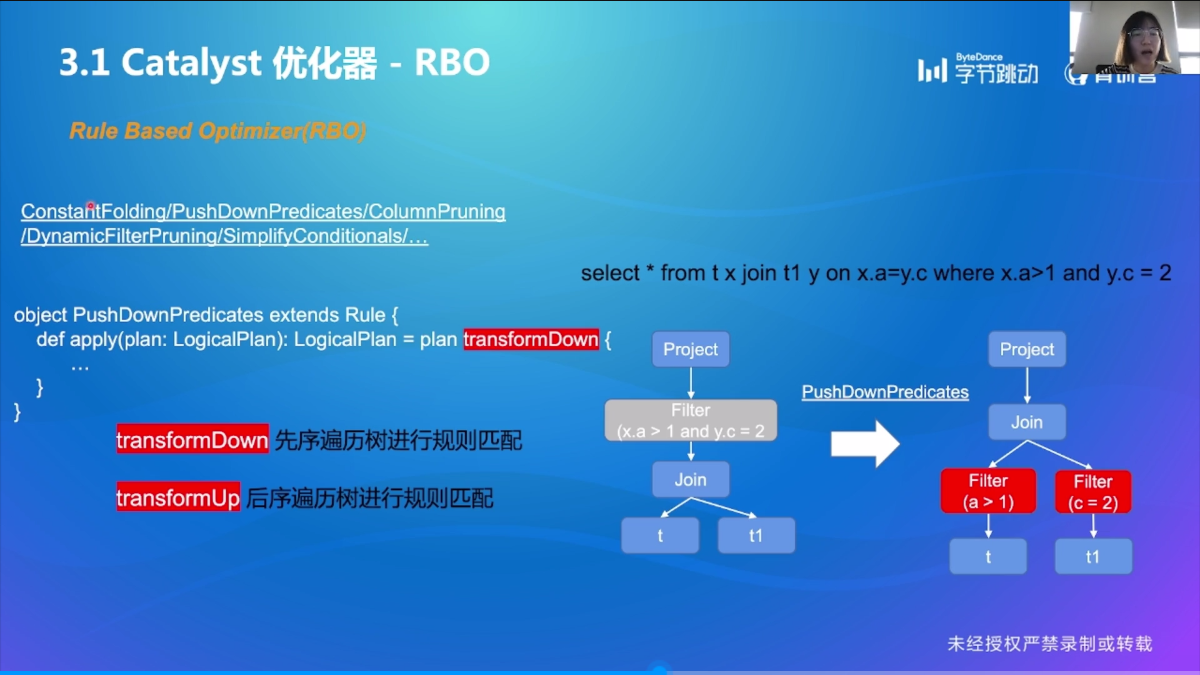
Catalyst 优化器

RBO
语法树遍历->模式匹配->等价转换
CBO

Adaptive Query Excution
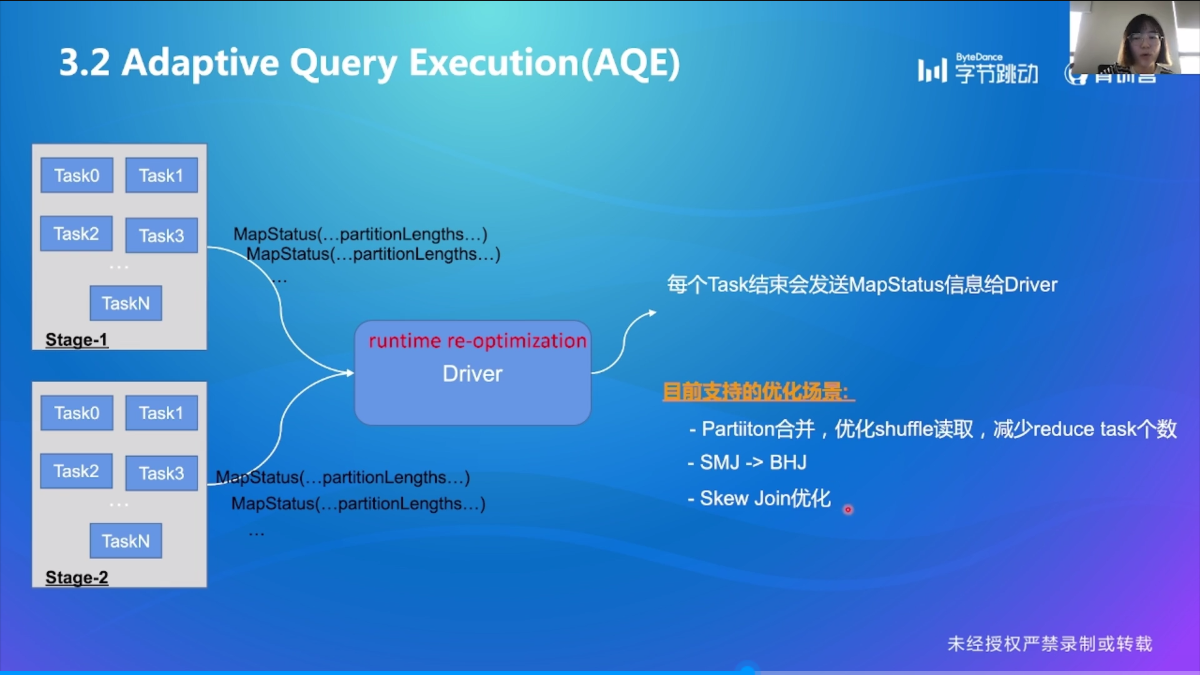
Coalescing Shuffle Partition
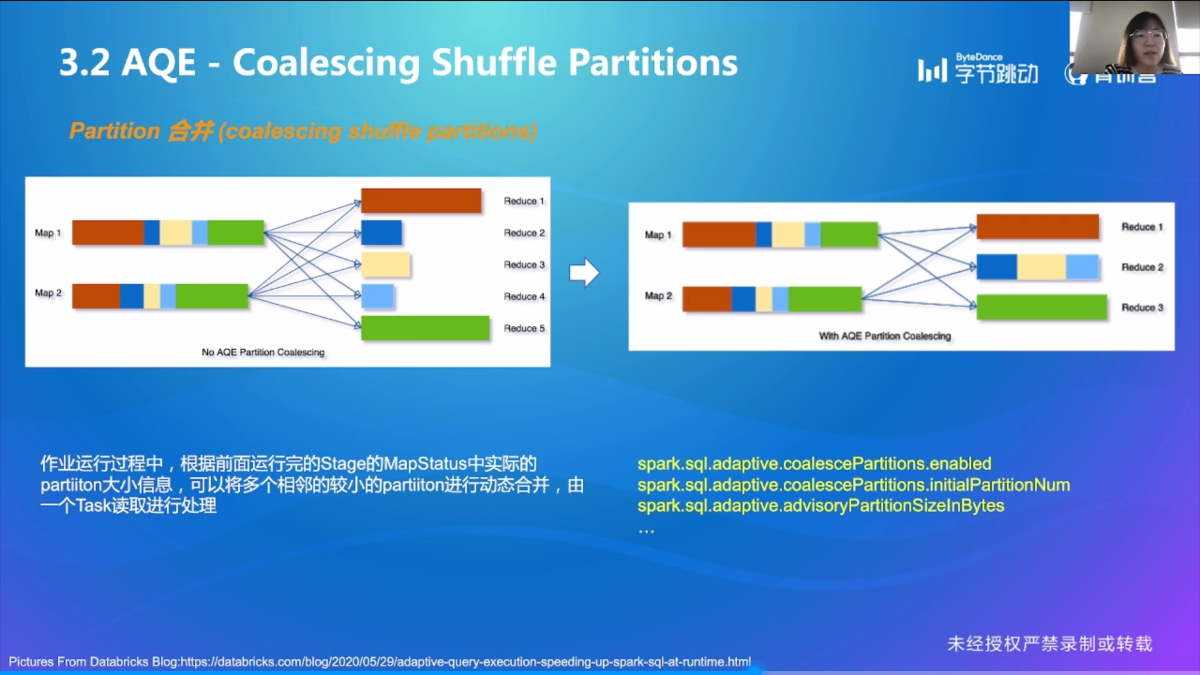
先设置比较大的 Partition 个数,然后后面再动态合并
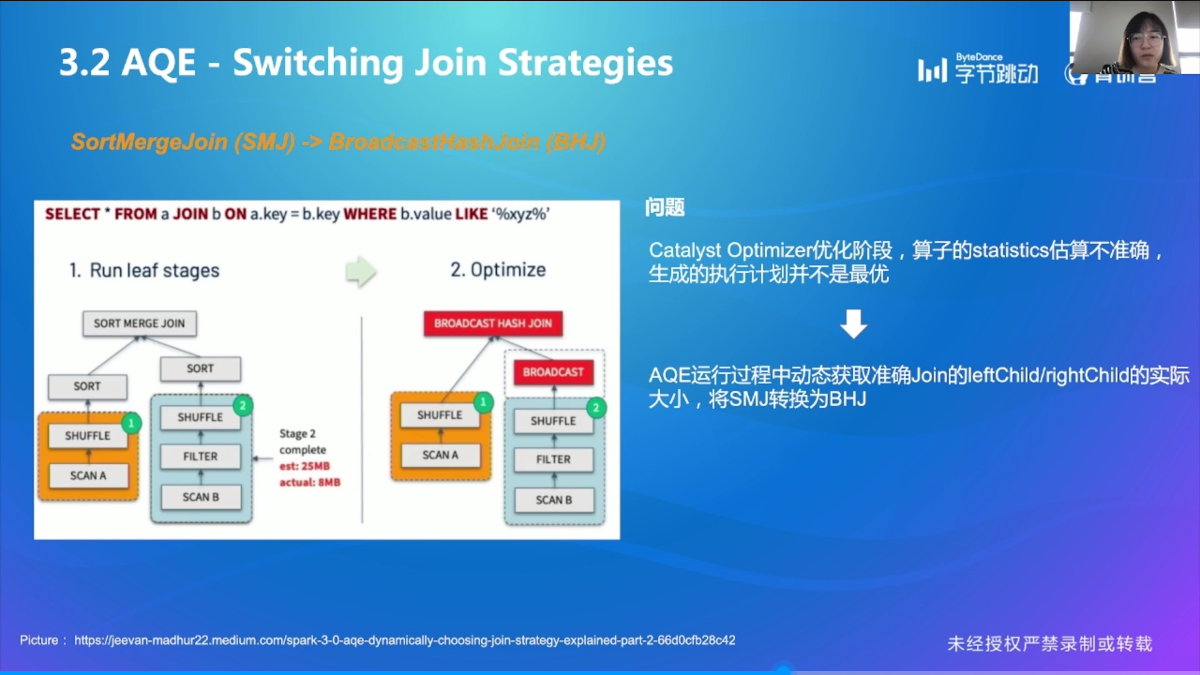
Switch Join Strategies
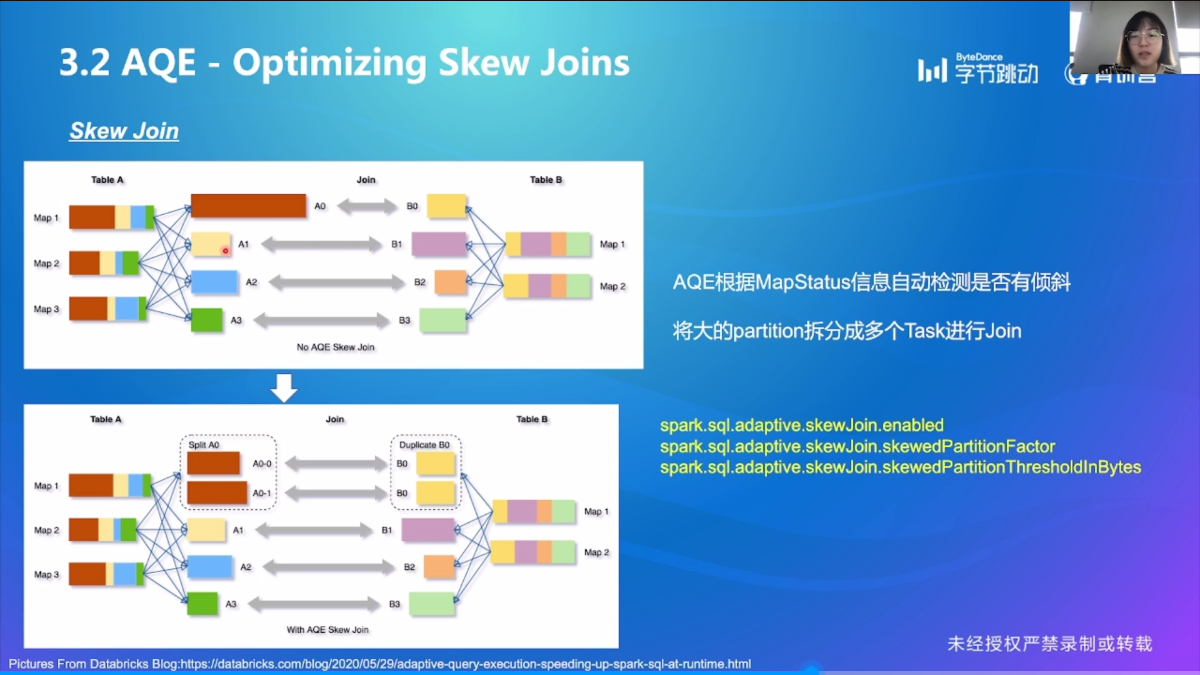
Optimizing Skew Joins
Runtime Filter
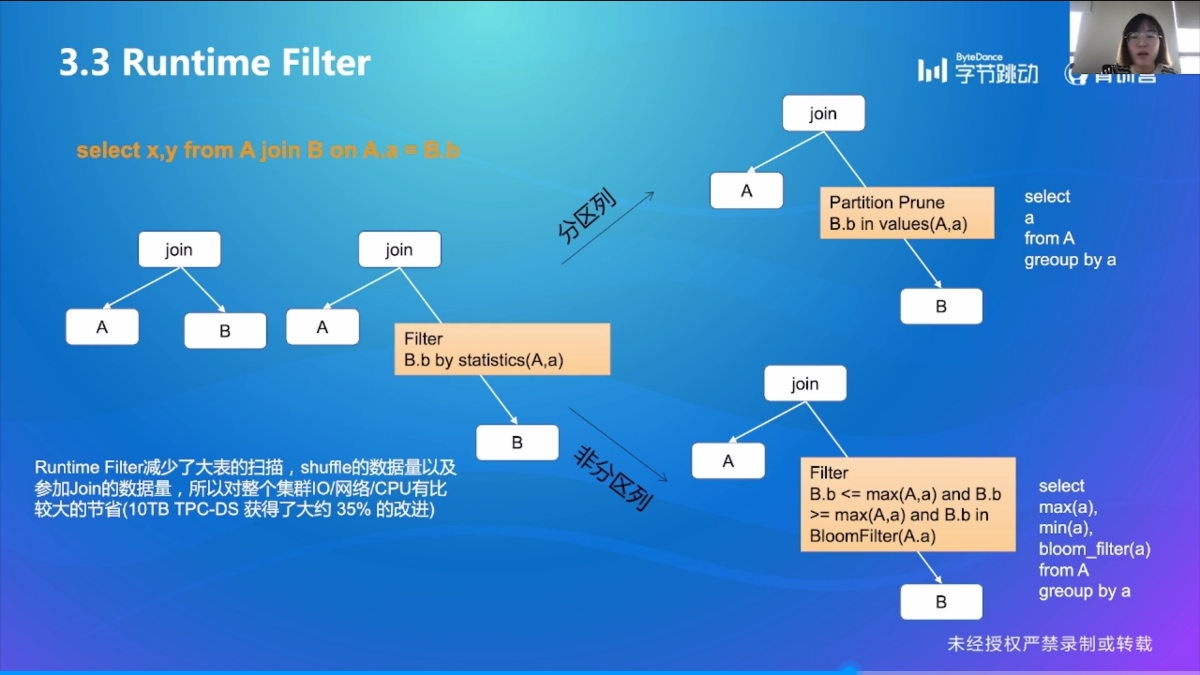
这个和第一课里面讲的一样
Bloom Runtime Filter

Codgen
Expression

WholeStageCodegen

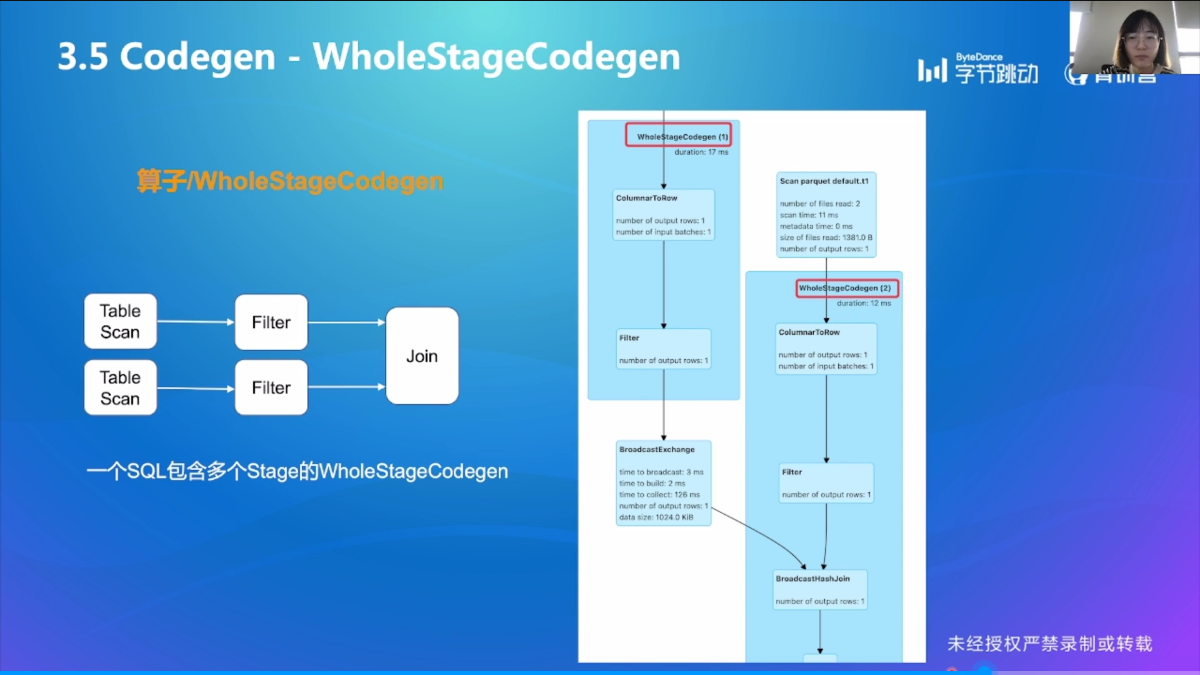
业界挑战与实践
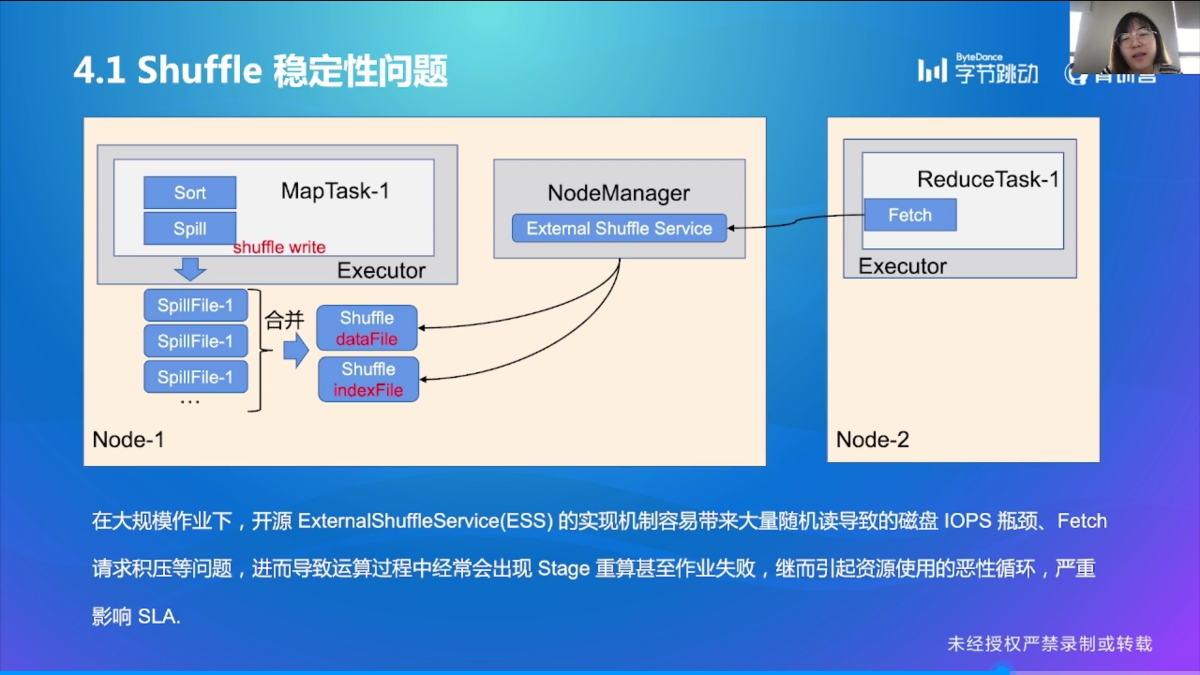
Shuffle 稳定性问题

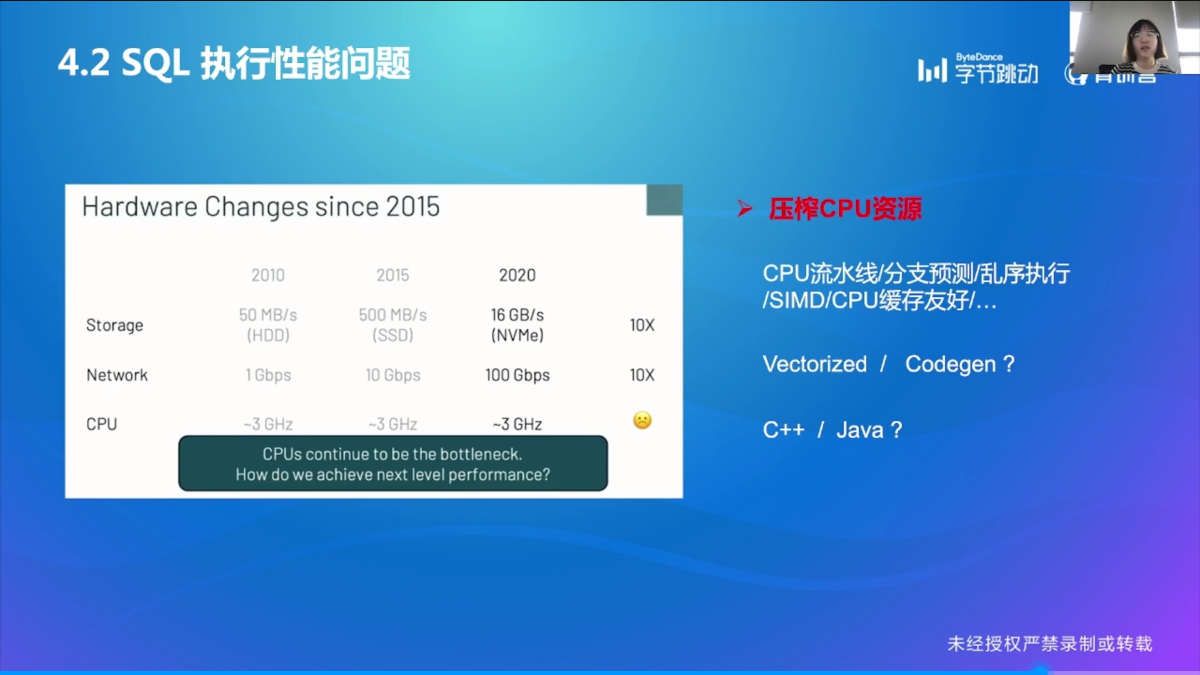
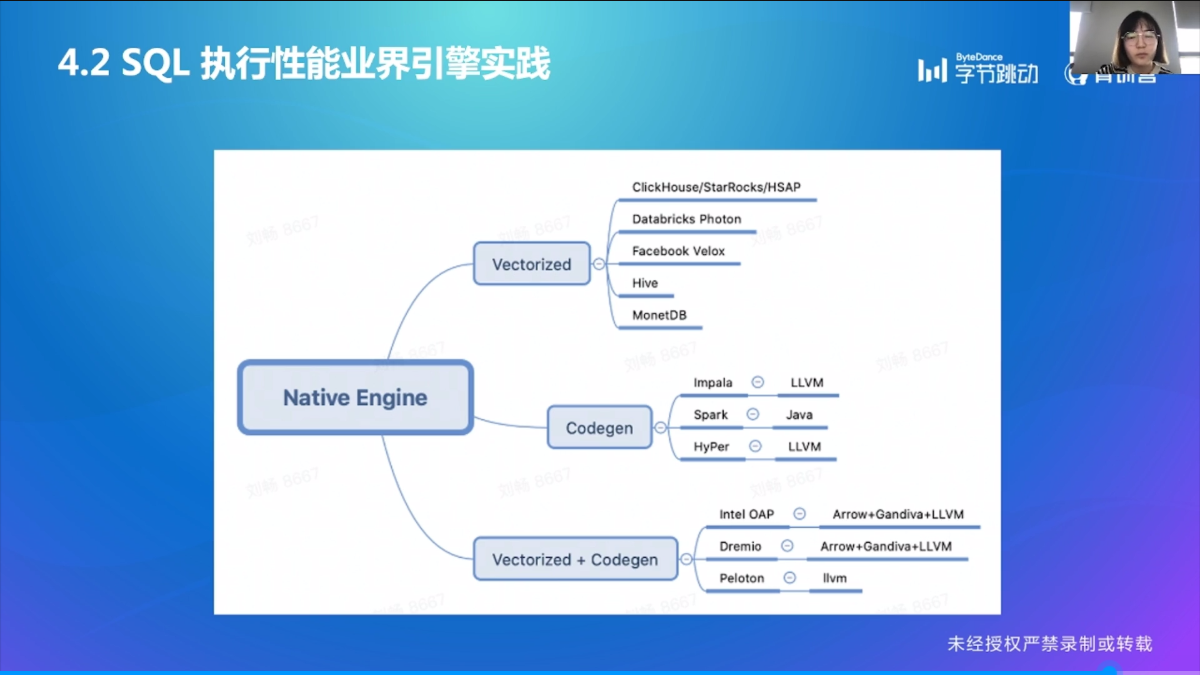
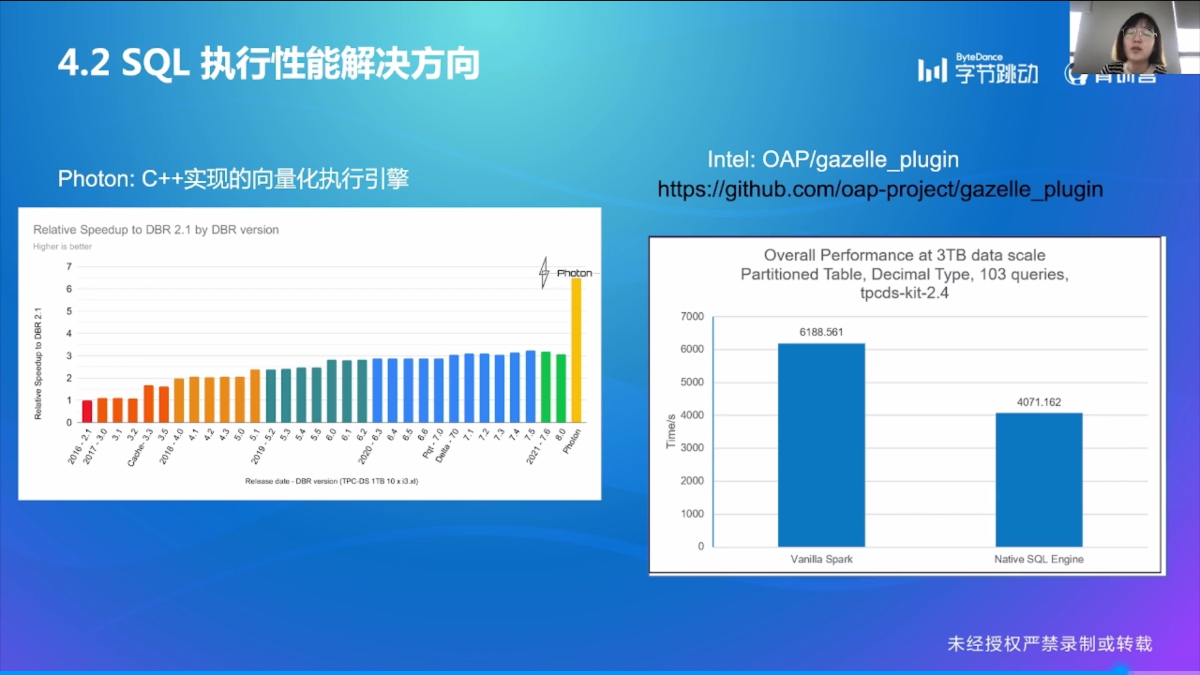
SQL 执行性能问题
参数推荐/作业诊断

总结

评论
GiscusTwikoo