
『字节青训营-3rd』L3:高质量编程与性能调优实战
前情提要:
高质量编程
高质量编程简介
什么是高质量:编写的代码能够达到正确可靠、简洁清晰的目标
- 各种边界条件是否考虑完备
- 异常情况处理,稳定性保证
- 易读易维护
编程原则:
- 简单性
- 可读性
- 团队生产力
编码规范
如何编写高质量 Go 代码
- 代码格式
- 注释
- 命名规范
- 控制流程
- 错误和异常处理
代码格式
推荐使用 gofmt 等工具自动格式化代码
gofmt
官方的自动格式化工具
goimports
能自动控制库的引用
注释
注释应该做的
-
解释代码作用(适合注释公共符号)
-
解释代码是如何做的(适合注释实现过程)
-
解释代码实现的原因(适合解释代码的外部因素,提供额外上下文)
-
解释代码什么情况会出错(适合解释代码的限制条件)
-
公共符号始终要注释
- 包中声明的每个公共的符号:变量、常量、函数以及结构都需要添加注释
- 任何既不明显也不简短的公共功能必须予以注释
- 无论长度或复杂程度如何,对库中的任何函数必须进行注释
有一个例外,不需要注释实现接口的方法
小结
- 代码是最好的注释
- 注释应该提供代码未表达出的上下文信息
命名
variable
-
简洁胜于冗长
-
缩略词全大写,但当其位于变量开头且不需要导出时,使用全小写
- 例如使用
ServeHTTP而不是ServeHttp - 使用
XMLHTTPRequest或者xmlHTTPRequest
- 例如使用
-
变量距离其被使用的地方越远,则需要携带越多的上下文信息
-
全局变量在其名字中需要更多的上下文信息,使得在不同地方可以轻易辨认出其含义
function
- 函数名不携带包名的上下文信息,因为包名和函数名总是成对出现的
- 函数名尽量简短
- 当名为 foo 的包某个函数返回类型 Foo 时,可以省略类型信息而不导致歧义
- 当名为 foo 的包某个函数返回类型 T 时(T 并不是 Foo),可以在函数名中加入类型信息
package
- 只由小写字母组成。不包含大写字母和下划线等字符
- 简短并包含一定的上下文信息。例如 schema、task 等
- 不要与标准库同名。例如不要使用 sync 或者 strings
尽量满足的规则:
- 不使用变量名作为包名
- 使用单数而不是复数
- 谨慎使用缩写
小结
- 核心目标是降低阅读理解代码的成本
- 重点考虑上下文信息,设计简洁清晰的名称
控制流程
-
避免嵌套,保持正常流程清晰
1
2
3
4
5
6
7
8
9
10
11
12// Bad
if foo {
return x
} else {
return nil
}
// Good
if foo {
return x
}
return nil -
尽量保持正常代码路径为最小缩进
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// Bad
func OneFunc() error {
err := doSomething()
if err := nil {
err := doAnotherThing()
if err == nil {
return nil
}
return err
}
return err
}
// Good
func OneFunc() error {
if err := doSomething(); err != nil {
return err
}
if err := doAnotherThing(); err != nil {
return err
}
return nil
} -
小结
-
线性原理,处理逻辑尽量走直线,避免复杂的嵌套分支
-
提高代码的可读性
-
错误与异常处理
简单错误
简单错误指仅出现一次的错误,且在其他地方不需要捕获该错误
优先使用 errors.New 创建匿名变量来直接表示简单错误
如果有格式化的需求,使用 fmt.Error
1 | // https://github.com/golang/go/blob/master/src/net/http/client.go#L802 |
错误的 Wrap 和 Unwrap
将一个 error 嵌套进另一个 error 中,从而生成一个 error 的跟踪链
从 Go1.13 后,可以在 fmt.Errorf 中使用 %w 关键字来将一个错误 wrap 至其错误链中
1 | // https://github.com/golang/go/blob/master/src/cmd/go/internal/work/exec.go#L983 |
错误判定
-
使用
errors.Is可以判定错误链上的所有错误是否含有特定的错误1
2
3
4
5
6
7// https://github.com/golang/go/blob/master/src/cmd/go/internal/modfetch/sumdb.go#L208
data, err = lockedfile.Read(targ)
if errors.Is(err, fs.ErrNotExist) {
// Treat non-existent as empty, to bootstrap the "latest" file
// the first time we connect to a given database.
return []byte{}, nil
} -
在错误链上获取特定种类的错误,使用
errors.As1
2
3
4
5
6
7
8
9// https://github.com/golang/go/blob/master/src/errors/wrap_test.go#L255
if _, err := os.Open("non-existing"); err != nil {
var pathError *fs.PathError
if errors.As(err, &pathError) {
fmt.Println("Failed at path:", pathError.Path)
} else {
fmt.Println(err)
}
}
panic
- 不建议在业务代码中使用 panic
- 如果当前 goroutine 中所有 deferred 函数都不包含 recover 就会造成整个程序崩溃
- 当程序启动阶段发生不可逆转的错误时,可以在 init 或 main 函数中使用 panic
recover
- recover 只能在被 defer 的函数中使用,嵌套无法生效,只在当前 goroutine 生效
- 如果需要更多的上下文信息,可以 recover 后在 log 中记录当前的调用栈。
性能优化建议
Slice
- 在尽可能的情况下,在使用 make() 初始化切片时提供容量信息,特别是在追加切片时
- 在已有切片的基础上进行切片,不会创建新的底层数组。因为原来的底层数组没有发生变化,内存会一直占用,直到没有变量引用该数组。因此很可能出现这么一种情况,原切片由大量的元素构成,但是我们在原切片的基础上切片,虽然只使用了很小一段,但底层数组在内存中仍然占据了大量空间,得不到释放。推荐的做法,使用 copy 替代 re-slice
Map
和 Slice 一样,应该根据实际需求提前预估好需要的空间
字符串处理
-
常见的字符串拼接方式
+strings.Builderbytes.Buffer
-
strings.Builder最快,bytes.Buffer较快,+最慢 -
原理
-
字符串在 Go 语言中是不可变类型,占用内存大小是固定的,当使用 + 拼接 2 个字符串时,生成一个新的字符串,那么就需要开辟一段新的空间,新空间的大小是原来两个字符串的大小之和
-
strings.Builder,bytes.Buffer 的内存是以倍数申请的
-
strings.Builder 和 bytes.Buffer 底层都是 []byte 数组,bytes.Buffer 转化为字符串时重新申请了一块空间,存放生成的字符串变量,而 strings.Builder 直接将底层的 []byte 转换成了字符串类型返回
-
空结构体
- 空结构体不占据内存空间,可作为占位符使用
- 比如实现简单的 Set
- Go 语言标准库没有提供 Set 的实现,通常使用 map 来代替。对于集合场景,只需要用到 map 的键而不需要值
atomic 包
对于变量来说,建议使用 atomic 来代替 sync.Mutex
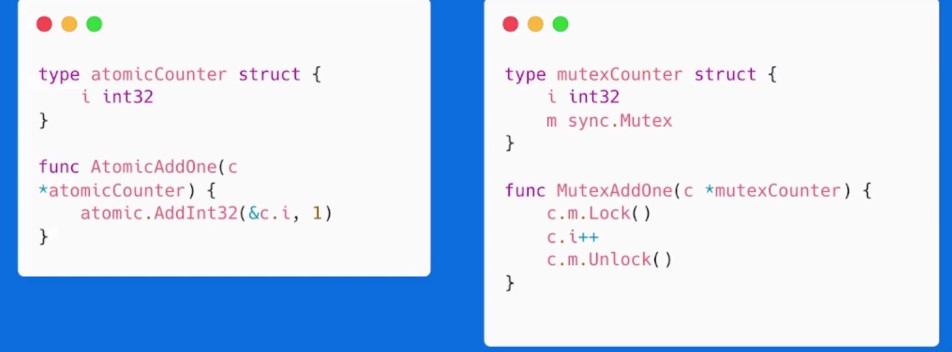
原理
- 锁的实现是通过操作系统来实现,属于系统调用,
atomic操作是通过硬件实现的,效率比锁高很多 sync.Mutex应该用来保护一段逻辑,不仅仅用于保护一个变量- 对于非数值系列,可以使用
atomic.Value,atomic.Value能承载一个interface{}
小结
-
避免常见的性能陷阱可以保证大部分程序的性能
-
针对普通应用代码,不要一味地追求程序的性能,应当在满足正确可靠、简洁清晰等质量要求的前提下提高程序性能
性能调优实战
性能调优简介
- 要依靠数据不是猜测
- 要定位最大瓶颈而不是细枝末节
- 不要过早优化
- 不要过度优化
性能分析工具 pprof 实战
功能简介
排查实战
搭建 pprof 实践项目
浏览器查看指标
CPU
- 命令:topN
- 命令:list
- 命令:web
Heap - 堆内存
- Top 视图
- Source 视图
goroutine - 协程
mutex - 锁
block - 阻塞
小结
采样过程和原理
小结
性能调优案例
基本概念
- 服务:能单独部署,承载一定功能的程序
- 依赖:Service A 的功能实现依赖 Service B 的响应结果,称为 Service A 依赖 Service B
- 调用链路:能支持一个接口请求的相关服务集合及其相互之间的依赖关系
- 基础库:公共的工具包、中间件
业务优化
- 流程
- 建立服务性能评估手段
- 分析性能数据,定位性能瓶颈
- 重点优化项改造
- 优化效果验证
- 建立压测评估链路
- 服务性能评估
- 构造请求流量
- 压测范围
- 性能数据采集
- 分析性能火焰图,定位性能瓶颈
- pprof 火焰图
- 重点优化项分析
- 规范组件库使用
- 高并发场景优化
- 增加代码检查规则避免增量劣化出现
- 优化正确性验证
- 上线验证评估
- 逐步放量,避免出现问题
- 进一步优化,服务整体链路分析
- 规范上游服务调用接口,明确场景需求
- 分析业务流程,通过业务流程优化提升服务性能
基础库优化
- 适应范围更广,覆盖更多服务
- AB 实验 SDK 的优化
- 分析基础库核心逻辑和性能瓶颈
- 完善改造方案,按需获取,序列化协议优化
- 内部压测验证
- 推广业务服务落地验证
Go 语言优化
- 适应范围最广,Go 服务都有收益
- 优化方式
- 优化内存分配策略
- 优化代码编译流程,生成更高效的程序
- 内部压测验证
- 推广业务服务落地验证